
Hacker Bits, an awesome service that curates the best HackerNews stories each month into a stylish easy-to-read magazine, included my deployment story in their April 2016 edition (!). You can check it out here:

Hacker Bits, an awesome service that curates the best HackerNews stories each month into a stylish easy-to-read magazine, included my deployment story in their April 2016 edition (!). You can check it out here:
I recently learned something new about how retention rate calculations are performed and wanted to share. Consider this situation:
A user signs up for your service at 11:59pm on Tuesday, does something at 12:01am on Wednesday, leaves and never comes back again.
Should this user count towards your D1 retention rate?
When I initially built Retentioneer, a retention rate analysis script, it would say yes, the user should count towards the D1 retention rate because he was active on Tuesday then again on Wednesday.
But I realized that way of performing the calculation would inflate the D1 retention rate because it’s very common for a user to sign up for a service, try it out for a few minutes or an hour, then leave and never come back. Any of these users that overlapped midnight UTC would wind up inflating the D1 retention rate. In some test data I analyzed, D1 retention rate was 7% when D1 meant a user was active on adjacent calendar days, but only 2% when D1 meant users had to perform an event 24 – 48 hours after signing up (the magnitude of the difference will vary based on the type of service).
I decided the latter was a better reflection of the true retention rate, updated the script to perform the calculations that way, shipped it, and thought that was the end of it.
At some point though I got this idea in my head that most other analytics services don’t calculate retention rate this way because it would be too slow and that if a user is active at Tuesday and again on Wednesday, they are counted as retained. I wanted to standardize my script with these other services so it has been on my todo list for a while to revert Retentioneer to use the original calculation method.
But… turns out other analytics services do the calculations same way.
From Mixpanel’s How is retention calculated?:
Likewise, in daily retention, in order to be counted in the bucket marked 1, the customer must send whatever event we are looking for in the retention some time between 24 and 48 hours after he sent the cohortizing event.
And from Amplitude’s Retention: General and Computation Methods:
A user is counted as “next day” retained if they perform any event on at least the 24th-incremented hour. For instance, if a user performs their first event on Dec 1st, 05:59pm, the user is counted as Day 1 retained if they perform an event on Dec 2nd, 05:00pm, and Day 2 retained if they perform an event on Dec 3rd, 05:00pm.
Funny enough, there’s actually a note at the bottom of that page that explains Amplitude previously used calendar dates to perform the retention calculations:
Note: these computation methods only apply as far back to August 18, 2015. Any retention computations that include dates before August 18, 2015 will be computed by calendar days/weeks/months.
Awesome to see that they realized the issue and made the change.
To sum it up: a user should only count as D1 retained if they’ve been active 24 to 48 hours after performing the initial event. If you make the calculation using calendar days you’ll inflate the D1 retention rate.
Hat tip to my coworker Meredith for the always insightful discussions around this as well as Jan Piotrowski and Hrishi Mittal for their feedback on Twitter.
Yesterday my coworker Meredith and I were discussing retention rates and were stumped on what to call a certain retention metric. Specifically, what do you call the % of users that performed an event during the week following the user’s sign up date?
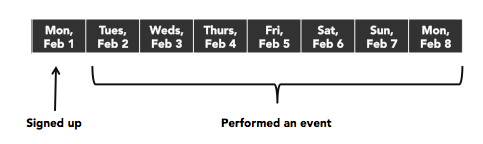
It’s an important metric to measure because for most services the sharpest drop-off will be the day users sign up so it’s useful to know what % of them return and use the service at some point in the week that follows.
I wound up tweeting about it and received a lot of responses which I’ll summarize below.
Before we dive into the options, it’s important to note that the day the user signed up is typically referred to as D0. Because users signed up that day, D0’s retention rate is always 100%. D1 then represents the % of users that were active on the day after sign up, D2 the % that were active two days after sign up, and so on.
Here are a few options with my 2c on their pros and cons:
Week 1 retention or Week 1 active – The main problem here is that it’s easy to misinterpret for folks seeing it for the first time: Does this mean a user was active 0 – 6 days after signing up (though this doesn’t make sense when you think about it because 100% of users are active on day 0) or 1 – 7 days (the first week after the sign up date)? Or if you confused it with the similarly-named 1 week retention does it mean 7 – 13 days (one week after the sign up date) or 8 – 14 days (one week after the day after sign up)? 😱
Post-first day active users, week one – +1 for specificity, -2 for the length :)
Week 0 retention or Week 0 active – This is less ambiguous, and is probably my second choice for what to call this metric. “Week 0 retention” would have to mean 1 – 7 days after sign up because a user isn’t considered retained on the sign up date and the zero makes it difficult to represent anything beyond days 1 – 7. The main problem for me is just that it takes too much thought and will constantly have to be explained to folks.
D1-7 – This is my favorite because there’s no ambiguity plus it’s nice and short. To me it’s hard to interpret this as anything but the metric we’re after. The downside is that it’s cumbersome to say out loud (“the day one to seven retention rate”) but in the end I think the pros outweigh that con. Hat tip Jan Piotrowski for suggesting it.
Thanks everyone for their feedback, especially Meredith who asked the question and whose insights on the naming I largely echoed in this post.
