At the end of 2022 I wrapped up my contract work with Help Scout and took the plunge to work on my indie software businesses full time. I’m now two years into that adventure, and wanted to share a periodic update about how things are going.
Preceden on the Back Burner
I made 32 commits to Preceden, my timeline maker software, the entire year. Those commits were all small tweaks like switching the AI timeline generator from gpt-3.5-turbo to gpt-4o-mini, fixing responsiveness issues, and other quick adjustments.
I check my support mailbox once or twice a week, and am usually able to respond to the handful of support requests I receive with saved replies, so support takes up almost no time.
Between the commits and support, I’d estimate I spent fewer than 10 hours working on Preceden the entire year.
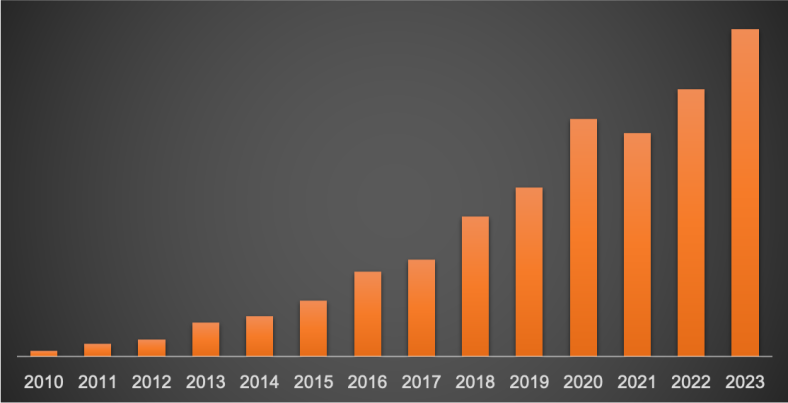
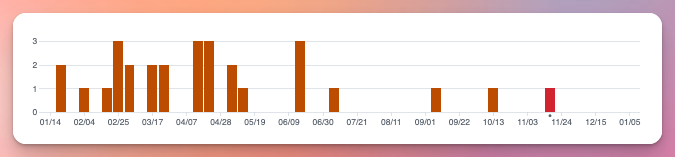
Despite that, SaaS revenue grew year-over-year, though only by 2%:
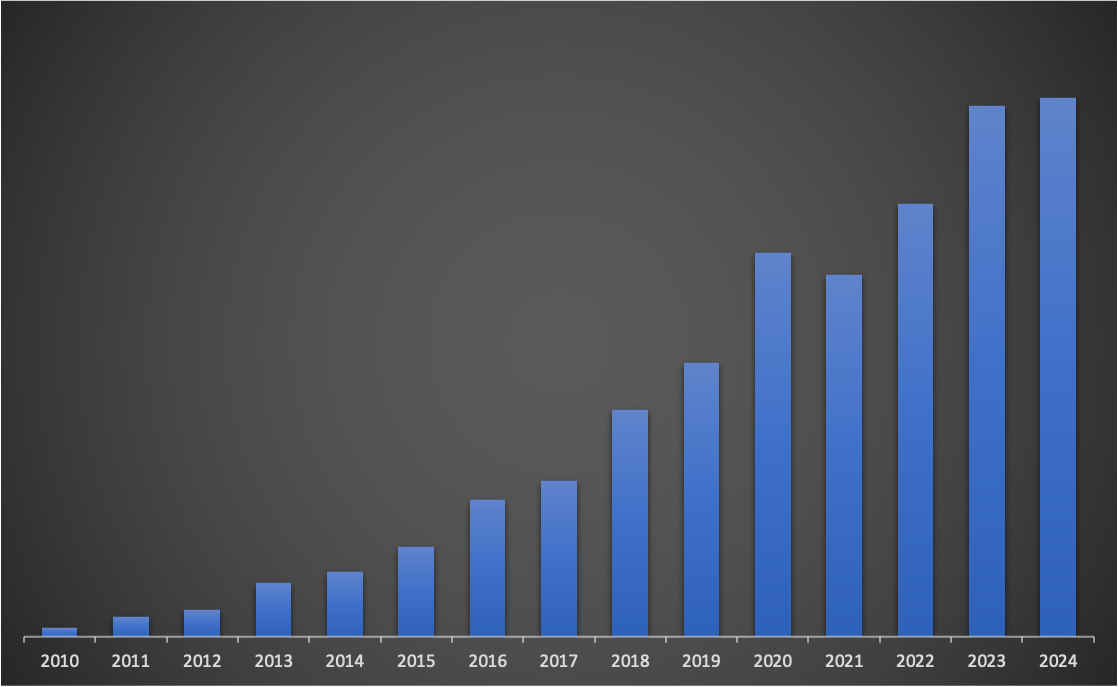
That’s the slowest growth rate its ever had, but also the highest hourly rate I’ve ever had 😂:
It’s likely that if I had invested more time into it, that revenue would have been higher, but it’s hard to say how much. To really move the needle on the revenue, I’d need to focus on increasing new MRR to offset the churn, and at this point that would largely come from marketing it more to increase top of the funnel traffic. That’s easier said than done in my experience, and not really what I want to spend my time working on.
In the fall I did have someone reach out about acquiring Preceden, but they didn’t seem too serious about it and it didn’t go anywhere. Still, it was interesting to consider whether I wanted to sell it, and if so for how much, and how it would impact my life if I did sell it. After all, I could still sell it anytime, even if it’s through FE International or Acquire. Having a few years of future Preceden income in the bank would be nice, but then (in the absence of other income) I’d be eating into those savings each month to pay the bills vs using Preceden’s income each month. Psychologically I think the former would be much more difficult, even if the math indicated long term they’re not that different. Anyway, I’m not sure I want to sell it, but it’s also not completely off the table.
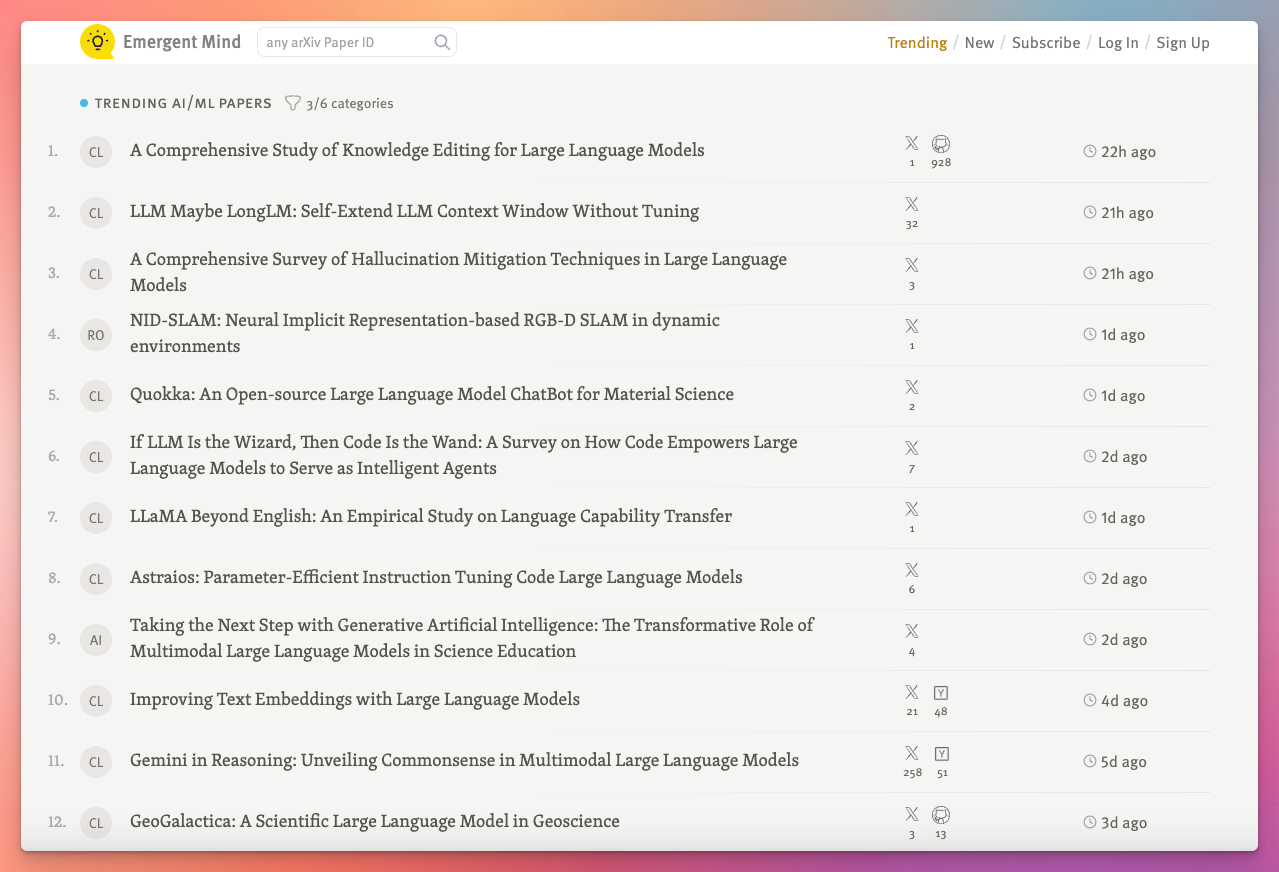
Emergent Mind: AI Research Assistant
The reason I didn’t work on Preceden was because I was focused on Emergent Mind.
Those of you who have been following me for a while know some of this, but to quickly recap where I was a year ago:
- Dec 2022 – Jan 2023 – it was called LearnGPT, and was for sharing ChatGPT examples. Almost sold it, but decided not to.
- Feb 2023 – Jan 2024 – renamed it to Emergent Mind, pivoted to an AI news aggregator. Almost shut it down, but decided not to.
- Jan 2024 – pivoted to an AI research aggregator, went full time on it
Thankfully, there were no hard pivots in 2024, even though the product looks a lot different now than it did a year ago. Instead, I focused on taking that initial AI research aggregator and building it into a proper AI research assistant that people could use to discover and learn about research. I’ve been building it up iteratively:
- Feb 2024 – Expanded beyond the few initial AI/ML arXiv categories it was aggregating (#)
- May 2024 – Expanded to all computer science categories (#)
- June 2024 – Added some basic semantic search capabilities with topic definitions (#)
- July 2024 – Focused the homepage on search (#)
- Aug 2024 – Added quick answers to surface relevant research when users perform searches (#)
- Sept 2024 – Soft launched v1 AI Research Assistant that synthesizes complete answers from research (#)
- Oct 2024 – Publicly launched the AI Research Assistant (#)
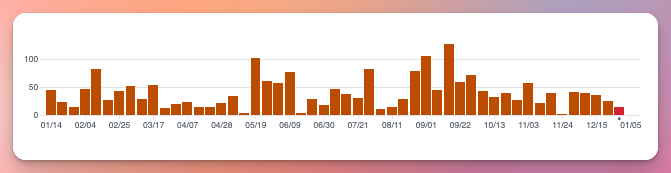
And many smaller improvements and updates in between and since, totaling 2,200 commits:
You can see me giving a demo of the mostly-current research assistant in this video:
Omar Olivares , an AI engineer who helps me with Emergent Mind, took the initiative to have us sponsor the 27th Iberoamerican Congress on Pattern Recognition in Chile, which got the site in front of a lot of people:






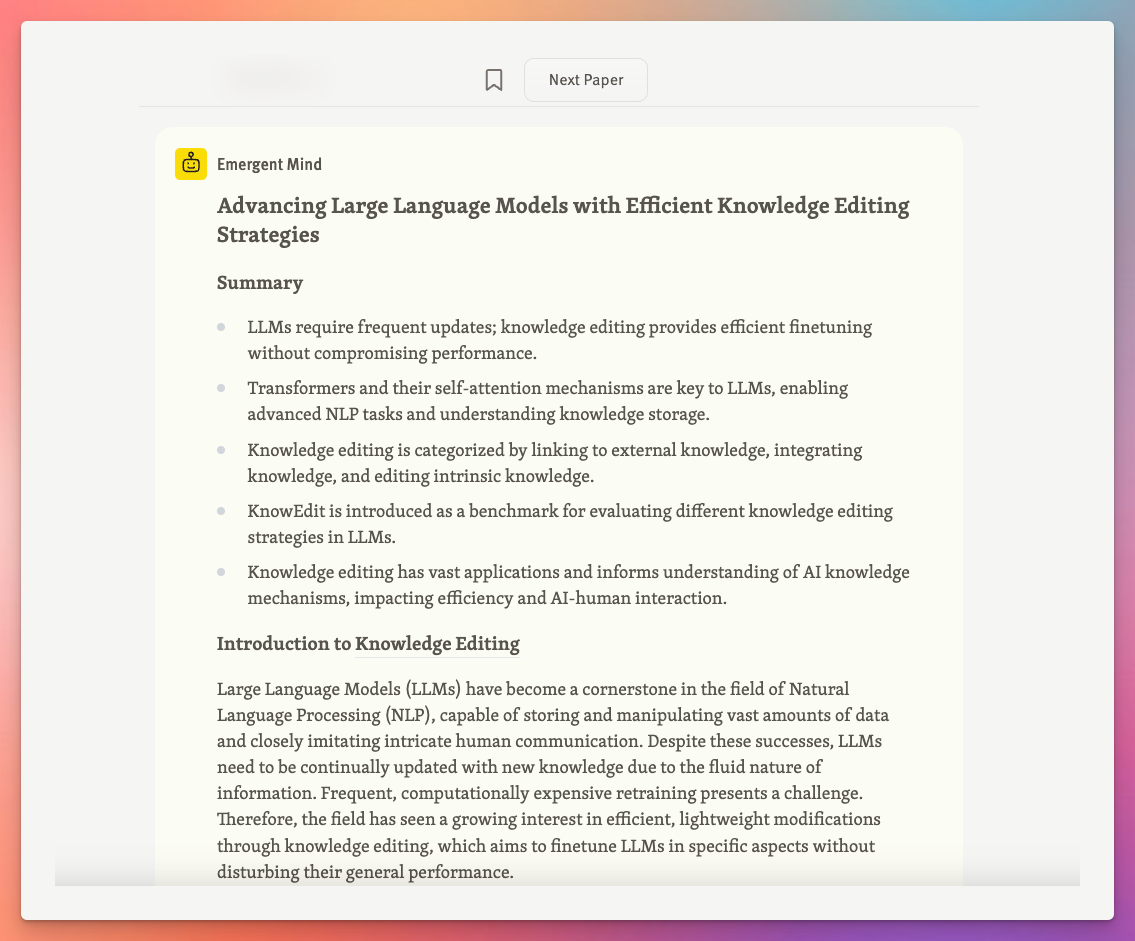
The last major update was the public launch of the AI research assistant for computer scientists in October. Behind the scenes, I’ve been working on building out the platform so it’s able to perform very sophisticated analyses of research using LLMs. It’s not there yet, but I think there’s a decent chance that in 2025 Emergent Mind will become a best-in-class product for its research synthesis capabilities.
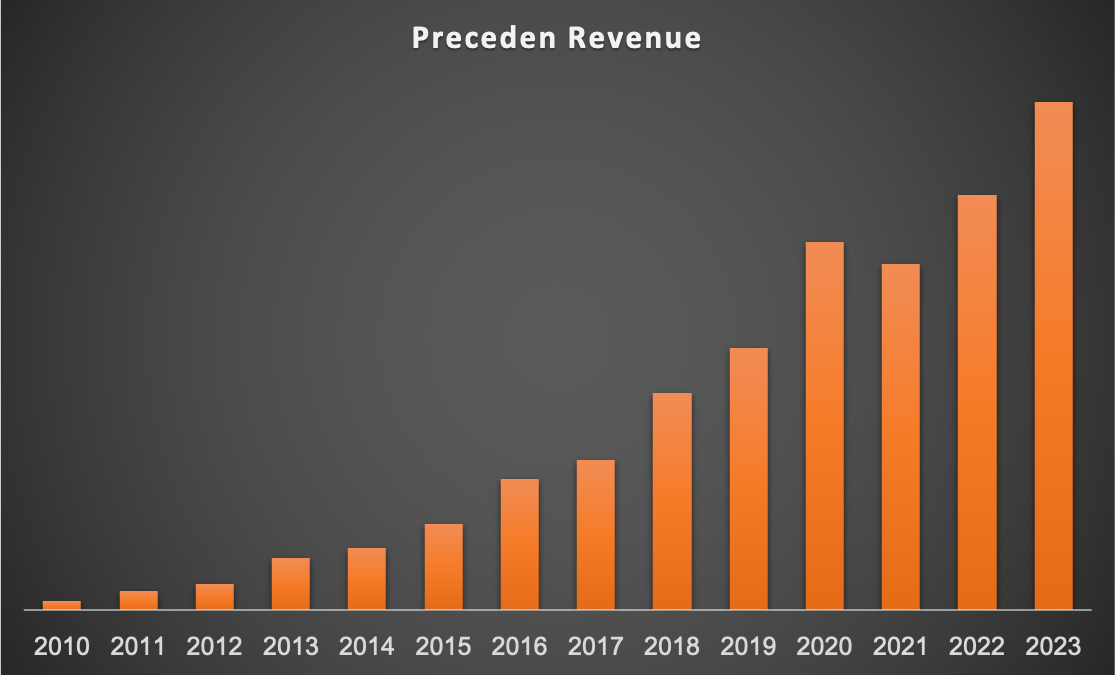
As far as how it’s doing as a business, revenue is up and to the right despite there being a lot of room for improvement with the current plans and pricing and not doing nearly enough marketing:
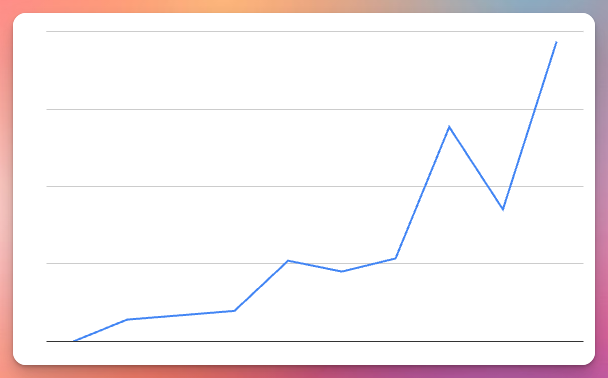
So what’s the end goal here?
I started Emergent Mind right after ChatGPT launched with the simple goal of building a great product in the AI space. The first two iterations (the ChatGPT examples site and AI news aggregator) were okay, but ultimately not interesting enough to continue with. Some good came out of them though, because they led me into the research space, which I’m now fascinated with and think I can have an impact in by building AI tools for scientists, engineers, and researchers to do better research.
I’m in a weird spot too where I have this $10k+ MRR passive income business with Preceden that makes enough to support me, and while getting Emergent Mind there too would be great, it seems kind of like a hollow goal, and a missed opportunity to set a different, more ambitious type of goal.
The way I’ve started thinking about it is that my mission with Emergent Mind is to build a product that contributes to someone making a scientific discovery that has a significant positive impact on the world.
It sounds kind of delusional, I know, but I think the platform is actually very well positioned to do that in the future.
That mission also provides clarity on questions that might have different answers if the goal was to build a big business to sell to Google. For example:
- Should it stay focused on computer science or expand to other fields? Expand, because the tools can benefit researchers in other fields too.
- Should it be a purely paid product? No, better to be generous, because the more people using it, the more it’s likely to benefit their research.
- Which of the dozens of ideas on my todo list should I work on next? Whichever is most likely to help users do better research.
- Should I try to raise a seed round to move faster? Maybe? (If you’re in a position to help, lets chat.)
We’ll see how this all goes. It might not play out like this, but it seems very much worth trying, and I’m enjoying the journey.
Also, if you have any suggestions on Preceden or Emergent Mind, please drop me a note, I’d very much value that feedback.
Until next time 👋