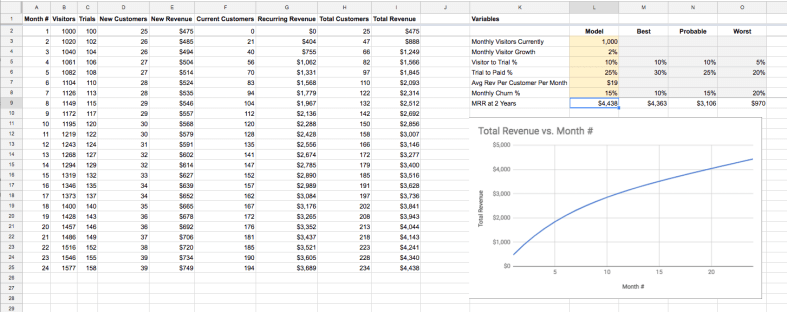
One of the main ways we evangelize metrics at Help Scout is with a daily metrics report that is automatically emailed to the entire company every morning.
In the email we highlight the performance of our key business metrics (New Trials, New Customers, etc) for the day prior and for the month to date. We also include our projection and target for the month to help us understand how we’re doing for the month.
Here’s what it looks like (with a shortened list of metrics and no actual numbers):
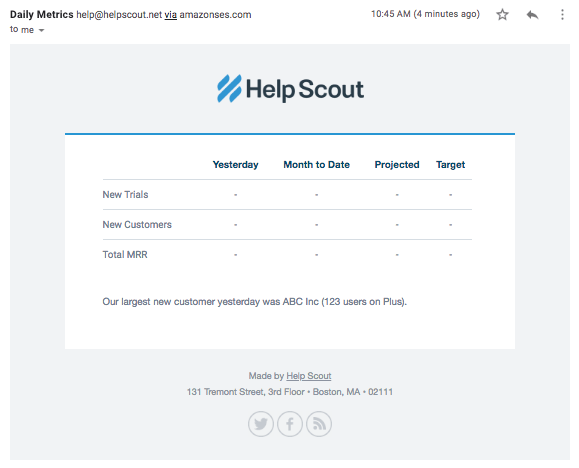
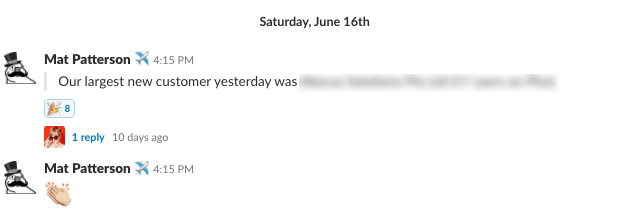
Because the report is delivered over email and doesn’t require logging into a separate tool, it makes it easy for everyone to keep up to date about how the business is doing. It’s also a frequent cause for celebration in Slack:
In years past a prior version of this report was generated with a lot of PHP code that was responsible for calculating all of the metrics and delivering the email.
When we adopted Looker as our Business Intelligence tool last year we ran into a problem though because we had refined how a lot of our metrics were calculated as we implemented them in Looker. As a result, Looker would sometimes report different values than daily metrics report. This obviously wasn’t ideal because it caused people to mistrust the numbers: if Looker said we made $1,234 yesterday but the metrics email said we made $1,185, which was correct?
Our solution was to rebuild the daily metrics email to use Looker as the single source of truth for our metrics. Rather than calculate the metrics one way in Looker and painstakingly try to keep the PHP logic in sync, we rebuilt the metrics email from scratch in Ruby and used Looker’s API to pull in the values for each of the metrics. This ensured that the numbers in Looker and the daily metrics email always matched since the daily metrics email was actually using the metrics calculated by Looker.
Building a Daily Metrics Report for your business
If you use Looker and want to build something similar for your organization (which I highly recommend!), I open sourced a super-simple version of ours to help you get started:
https://github.com/mattm/looker-daily-metrics-email
For this demo, it assumes you have a Look with a single value representing the number of new customers your business had yesterday:

When you run the script, it will query Looker for this value, throw it into a basic HTML-formatted email, and deliver it:

You will of course want to customize this for your business, make the code more robust, style the email, etc – but this should save you some time getting it off the ground.
If you run into any issues feel free to reach out. Good luck!
Edit: Here’s a recording of a talk from JOIN 2018 I gave on this topic.