What I’m Working On
At Preceden, I’ve been thinking a lot about data retention. For example, it has users that signed up a decade ago, used it briefly, and then never again. Unless they deleted their account, their user and timeline data still exist in Preceden’s database. In the past, I never gave any thought to whether it made sense to keep this data around forever. Maybe the user eventually returns one day, so why not keep it around? Analyzing all of that data has also been tremendously valuable. And for publicly shared timelines, there are SEO and user acquisition advantages to keeping those timelines around. But imagine a person that signed up in 2012 to create a private timeline about a messy divorce and hasn’t used it since then. Should Preceden retain that data forever? Probably not.
Addressing this is way easier said than done though. After I tweeted about this dilemma, Emilie Schario pointed me to an insightful Basecamp podcast episode about how they built something called the Data Incinerator to deal with this at their company. It’s worth a listen for anyone thinking about data retention. I’m probably going to build something like this to improve data retention in Preceden in the coming months.
—
Last summer I acquired Timeglider, a competitor timeline maker tool. I recouped the acquisition cost in two ways: I kept Timeglider running for its existing customers (which have continued to bring in revenue) and also redirected Timeglider’s homepage to Preceden (which brought in a lot of new customers for Preceden).
Because Timeglider hasn’t had any new sign ups in the last 14 months, its recurring revenue has gradually dwindled as its customers have churned. So the question I’ve been debating for a while now is how long to keep Timeglider running. On one hand, maintenance and costs are minimal, so it’s basically a small stream of completely passive income that would probably continue for years. On the other hand, the remaining recurring revenue wasn’t significant, most of the customers were inactive, its codebase and infrastructure are very brittle, and operating it takes up headspace that I’ve love to free up. After weighing it all, I decided earlier this week to announce it was shutting down at the end of November.
Executing on this plan took more work than I anticipated though.
- Many Timeglider customers paid annually. If someone paid $50 for access to Timeglider through August 2021, but I shut down the service in December 2020, it would be unethical to keep their full payment. I wound up issuing a lot of prorated refunds for recent annual payments.
- Stripe doesn’t provide a way in the UI to cancel multiple subscriptions at once. The quantity was more than I wanted to do manually, so had to write a little Ruby script to iterate over all of the subscriptions and cancel them.
- I added a prominent notice at the top of Timeglider with a link to FAQs about the closure including instructions on how to move their Timeglider timelines to Preceden.
- I had to notify all of the customers whose subscriptions I cancelled to make sure they knew the site was shutting down. Timeglider also has a free plan which had some active users, so I had to email them as well. Probably not the most efficient way to do this, but I BCC’d all of the impacted users 25 at a time in Help Scout (its BCC limit), using the Saved Reply functionality to compose each message.
- Most of the responses from users were understanding and they appreciated that I was giving them notice and also provided a way to move their timelines over to Preceden.
- There were some bugs I had to deal with though. By cancelling everyone’s subscriptions, it reverted everyone to Timeglider’s free plan which had feature limits including the inability to access more than 3 of their timelines. For users with more, this meant they couldn’t export their data. Had to hardcode in some logic to give everyone access to Timeglider’s top premium plan until the site shuts down.
Running that Ruby script to cancel all of the subscriptions was a little bit painful, but in the end I think shutting it down will be a good decision.
—
In my ongoing machine learning journey, I finished DataCamp’s Feature Engineering for NLP in Python course and started on its Introduction to TensorFlow in Python course. 8 courses including this one to completely finish the ML track.
—
At Help Scout, I started on a project to clean up our Looker instance. We’ve been using Looker for business intelligence reporting for more than 3 years and over that time we’ve accumulated hundreds of dashboards and more than a thousand individual Looks. We mostly try to organize these by function: a folder for marketing reporting, a folder for sales reporting, a folder for finance reporting, etc. But over time it’s gotten very messy. Lots of unused dashboards and Looks. Lots of duplicate reporting. Even some completely empty folders. For any employee venturing into Looker to try to understand our metrics, figuring out where to go was a challenge to say the least. I’ve been cleaning it up and with just a few hours of work so far it’s way, way better than it was. I regret not spending more time on it earlier.
What I’m Reading
The Psychology of Money by Morgan Housel. Really enjoyed this book. Lots of sage advice on how to think about personal finances, uncertainty, risk, etc. Morgan is worth following on Twitter too. And for you podcast fans, here’s an interview with him from earlier this month (thanks Jason for the recommendation).
What I’m Watching
This deep dive explanation of a 3 minute Super Mario Bros 3 speed run is mind blowing:
I thought it was just going to be someone playing through the game perfectly, but it’s so much more than that. The record is made possible by painstaking work to reverse engineering the game to figure out and exploit a very subtle glitch. Here’s the HackerNews discussion about it.
What Else
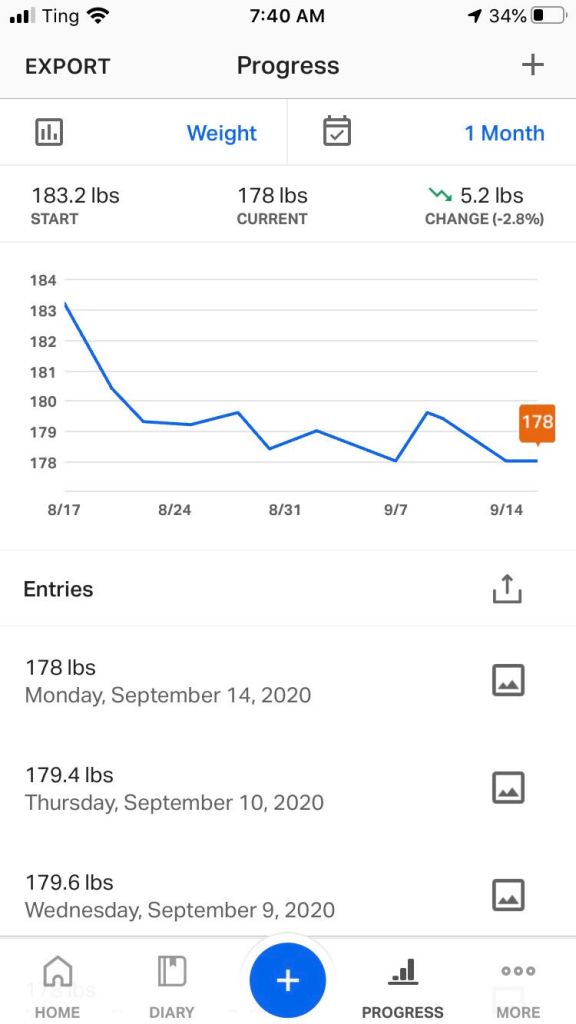
I wrapped up the 28-Day Keto Challenge. Writeup here. After being back on my normal carb-heavy diet now for 5 days and feeling like a glutton, I’m giving serious thought to going back on keto. We’ll see.
Hope everyone is doing well. Thanks for reading.