Similar to yesterday’s post on running Mistral 8x7Bs Mixture of Experts (MOE) model, I wanted to document the steps I took to run Mistral’s 7B-Instruct-v0.2 model on a Mac for anyone else interested in playing around with it.
Unlike yesterday’s post though, this 7B Instruct model’s inference speed is about 20 tokens/second on my M2 Macbook with its 24GB of RAM, making it something a lot more practical to play around with than the 10 tokens/hour MOE model.
These instructions are once again inspired by Einar Vollset’s post where he shared his steps, though updated to account for a few changes in recent days.
Update Dec 19: A far easier way to run this model is to use Ollama. Simply install it on your Mac, open it, then run ollama run mistral from the command line. However, if you want to go the more complex route, here are the steps:
1) Download HuggingFace’s model downloader
bash <(curl -sSL https://g.bodaay.io/hfd) -h
2) Download the Mistral 7B Instruct model
./hfdownloader -m mistralai/Mistral-7B-Instruct-v0.2
For me, I ran both of the commands above in my ~/code directory, and the downloader downloaded the model into ~/code/Storage/mistralai_Mistral-7B-Instruct-v0.2.
3) Clone llama.cpp and install the necessary packages
Using the GitHub CLI:
gh repo clone ggerganov/llama.cpp
And after you have it cloned, install the necessary packages:
python3 -m pip install -r requirements.txt
4) Move the 7B model folder into llama.cpp/models

5) Convert to F16
python3 convert.py models/mistralai_Mistral-7B-Instruct-v0.2 --outfile models/mistralai_Mistral-7B-Instruct-v0.2/ggml-model-f16.gguf --outtype f16
6) Quantize it
./quantize models/mistralai_Mistral-7B-Instruct-v0.2/ggml-model-f16.gguf models/mistralai_Mistral-7B-Instruct-v0.2/ggml-model-q4_0.gguf q4_0
7) Run it
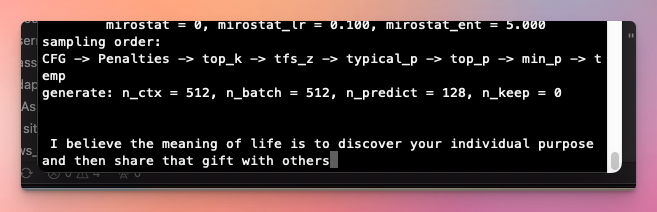
./main -m ./models/mistralai_Mistral-7B-Instruct-v0.2/ggml-model-q4_0.gguf -p "I believe the meaning of life is" -ngl 999 -s 1 -n 128 -t 8

Alternatively, run the built-in web server:
make -j && ./server -m models/mistralai_Mistral-7B-Instruct-v0.2/ggml-model-q4_0.gguf -c 4096

Unless you have a very powerful Macbook, definitely experiment with this model instead of the MOE model 🤣.