In January 2010 I soft-launched launched Preceden, a web-based timeline maker tool, followed a few weeks later by a larger launch on HackerNews:
Today – almost 13 years to the day since the initial launch – I’m going full time on it and I couldn’t be more excited.
A brief history of Preceden
At the time of Preceden’s launch, I was serving as a first lieutenant in the US Air Force and about halfway through a 5-year service commitment I incurred by attending the Air Force Academy, a military college. I knew I didn’t want to make the Air Force a career, so decided to start learning web development with the hope of eventually working full time on a startup after my service commitment ended in 2012.
The first web app I built during this time period was Domain Pigeon (a domain search tool), followed by Preceden, followed by Lean Designs (a WYSIWYG web design tool), followed by Lean Domain Search (another domain search tool I built while deployed to Iraq), plus a few smaller ones not worth mentioning.
By the time I left the Air Force, I had shut down all except Preceden and Lean Domain Search. I did go full time for a few months, but focused entirely on Lean Domain Search. That tool was eventually acquihired by Automattic in 2013, where I joined full time as a software engineer helping with the domain name experience on WordPress.com.
With Lean Domain Search in Automattic’s hands, I was left with just Preceden, which at that point was about 3 years old. It didn’t make much money at the time, but I decided to continue working on it as a side project and see where it went.
Four years later in 2017 I left Automattic to join Help Scout as their first data team hire (during my time at Automattic, I gradually shifted away from software engineering to more of a data analyst/analytics engineer role). I continued to work on Preceden (then 7 years old), and in 2018 I switched to a contractor role so I could put more time on Preceden.
And now, after 4 years of contracting, I’m finally going full time on Preceden.
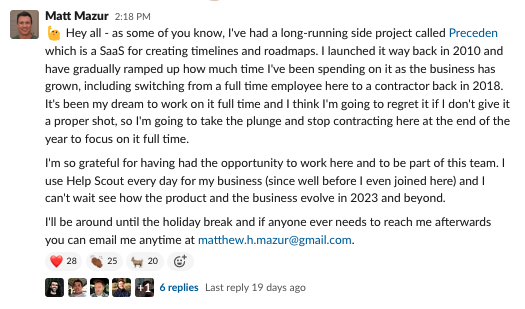
Here was my announcement at Help Scout from a few weeks ago:
Why not sooner?
It was a combination of things:
- I made a lot of rookie mistakes over the years that limited Preceden’s growth including not focusing on a specific niche, not spending enough time marketing, not talking to enough customers, trying to do too much myself, and just in general picking a difficult product and business to build (something I didn’t give any thought to initially).
- I was learning a ton, doing a lot of interesting work, and enjoying the camaraderie I had with my teammates at Automattic and later Help Scout.
- Financially it made more sense to keep Preceden as a side project.
On the last point – it’s much easier to launch a SaaS than it is to grow it to the point where it can replace your income. As the sole breadwinner in our household with 4 young kids, I was not comfortable going full time and merely being ramen profitable or anything close to it. I wanted to replace or mostly replace my other income, and with Preceden’s SaaS metrics being what they were, it just took a really, really long time to do that. The long slow SaaS ramp of death is something I now have a lot of experience with 😂.
But here I am, finally.
What’s next?
I plan to focus mostly on Preceden, but will spend some percentage of my time on other pursuits. I recently launched LearnGPT.com, a fledgling GPT education site, and will likely work more and more on AI projects including integrating it into Preceden itself.
Also, it’s been a busy few years, and I’m very much looking forward to relaxing more and spending more time with my family including my two younger kids who aren’t in school yet.
I don’t know what my future holds long term. Preceden’s finances are good enough for now, but not at a point where I can just stop working on it and coast for years. With a little luck, Preceden will continue to grow and will continue supporting me full time to either focus on it or other pursuits. There’s also some chance I get bored with it or stumble across some promising new startup and I wind up going back full time somewhere else. We will see!
I do hope to blog more frequently so if you are interested in following along, you can subscribe via email, RSS, or just follow me on Twitter at @mhmazur.
Thanks for reading 👋.