
I recently started making my way through An Introduction to Genetic Algorithms by Melanie Mitchell. I’m not too far into it yet but I’ve been pleasantly surprised by how clearly the author explains each concept.
In the first chapter she outlines a simple algorithm that is the basis for most applications of genetic algorithms. There isn’t any code in the book so I decided to implement it on my own in Ruby to understand it better:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| POPULATION_SIZE = 24 | |
| NUM_BITS = 64 | |
| NUM_GENERATIONS = 1000 | |
| CROSSOVER_RATE = 0.7 | |
| MUTATION_RATE = 0.001 | |
| class Chromosome | |
| attr_accessor :genes | |
| def initialize(genes = "") | |
| if genes == "" | |
| self.genes = (1..NUM_BITS).map{ rand(2) }.join | |
| else | |
| self.genes = genes | |
| end | |
| end | |
| def to_s | |
| genes.to_s | |
| end | |
| def count | |
| genes.count | |
| end | |
| def fitness | |
| genes.count("1") | |
| end | |
| def mutate! | |
| mutated = "" | |
| 0.upto(genes.length – 1).each do |i| | |
| allele = genes[i, 1] | |
| if rand <= MUTATION_RATE | |
| mutated += (allele == "0") ? "1" : "0" | |
| else | |
| mutated += allele | |
| end | |
| end | |
| self.genes = mutated | |
| end | |
| def &(other) | |
| locus = rand(genes.length) + 1 | |
| child1 = genes[0, locus] + other.genes[locus, other.genes.length] | |
| child2 = other.genes[0, locus] + genes[locus, other.genes.length] | |
| return [ | |
| Chromosome.new(child1), | |
| Chromosome.new(child2), | |
| ] | |
| end | |
| end | |
| class Population | |
| attr_accessor :chromosomes | |
| def initialize | |
| self.chromosomes = Array.new | |
| end | |
| def inspect | |
| chromosomes.join(" ") | |
| end | |
| def seed! | |
| chromosomes = Array.new | |
| 1.upto(POPULATION_SIZE).each do | |
| chromosomes << Chromosome.new | |
| end | |
| self.chromosomes = chromosomes | |
| end | |
| def count | |
| chromosomes.count | |
| end | |
| def fitness_values | |
| chromosomes.collect(&:fitness) | |
| end | |
| def total_fitness | |
| fitness_values.inject{|total, value| total + value } | |
| end | |
| def max_fitness | |
| fitness_values.max | |
| end | |
| def average_fitness | |
| total_fitness.to_f / chromosomes.length.to_f | |
| end | |
| def select | |
| rand_selection = rand(total_fitness) | |
| total = 0 | |
| chromosomes.each_with_index do |chromosome, index| | |
| total += chromosome.fitness | |
| return chromosome if total > rand_selection || index == chromosomes.count – 1 | |
| end | |
| end | |
| end | |
| population = Population.new | |
| population.seed! | |
| 1.upto(NUM_GENERATIONS).each do |generation| | |
| offspring = Population.new | |
| while offspring.count < population.count | |
| parent1 = population.select | |
| parent2 = population.select | |
| if rand <= CROSSOVER_RATE | |
| child1, child2 = parent1 & parent2 | |
| else | |
| child1 = parent1 | |
| child2 = parent2 | |
| end | |
| child1.mutate! | |
| child2.mutate! | |
| if POPULATION_SIZE.even? | |
| offspring.chromosomes << child1 << child2 | |
| else | |
| offspring.chromosomes << [child1, child2].sample | |
| end | |
| end | |
| puts "Generation #{generation} – Average: #{population.average_fitness.round(2)} – Max: #{population.max_fitness}" | |
| population = offspring | |
| end | |
| puts "Final population: " + population.inspect |
The algorithm as described in the book is quoted below with my comments following each section.
1. Start with a randomly generated population of n l-bit chromosomes (candidate solutions to a problem).
In this code, n is represented by the POPULATION_SIZE constant and l by NUM_BITS. The initial randomly generated population is created using the Population’s seed! method.
2. Calculate the fitness f(x) of each chromosome x in the population.
The fitness of a Chromosome can be calculated by its fitness method. In this example, the fitness is simply the number of 1’s that the chromosome contains.
3. Repeat the following steps until n offspring have been created:
a. Select a pair of parent chromosomes from the current population, the probability of selection being an increasing function of fitness. Selection is done “with replacement,” meaning that the same chromosome can be selected more than once to become a parent.
A chromosome is chosen from the population using the Population’s select method. This method implements fitness-proportionate selection using roulette-wheel sampling which is conceptually equivalent to giving each individual a slice of a circular roulette wheel equal in area to the individual’s fitness. The roulette wheel is spun, the ball comes to resent on one wedge-shaped slice, and the corresponding individual is selected.
b. With probability Pc (the “crossover probability” or “crossover rate”), cross over the pair at a randomly chosen point (chosen with uniform probability) to form two offspring. If no crossover takes place, form two offspring that are exact copies of their respective parents.
The crossover probability is defined by CROSSOVER_RATE. The crossover is performed by the Chromosome’s bitwise AND (&) operator which I overloaded for this class.
c. Mutate the two offspring at each locus with probability Pm (the mutation probability or mutation rate), and place the resulting chromosomes in the new population. If n is odd, one new population member can be discarded at random.
The mutation rate is defined by the MUTATION_RATE constant. The mutation is performed by the Chromosome’s mutate! method.
4. Replace the current population with the new population.
5. Go to step 2.
Here are the results for 1,000 generations where the population is 24, the number of bits per chromosome is 64, the mutation rate is 0.001, and the crossover rate is 0.7. Pay attention to the average value over time:
Generation 1 - Average: 32 - Max: 40 Generation 2 - Average: 33 - Max: 38 Generation 3 - Average: 34 - Max: 41 Generation 4 - Average: 34 - Max: 37 Generation 5 - Average: 34 - Max: 41 Generation 6 - Average: 35 - Max: 39 Generation 7 - Average: 34 - Max: 43 Generation 8 - Average: 35 - Max: 45 Generation 9 - Average: 36 - Max: 44 Generation 10 - Average: 37 - Max: 44 ... Generation 990 - Average: 49 - Max: 50 Generation 991 - Average: 49 - Max: 50 Generation 992 - Average: 49 - Max: 51 Generation 993 - Average: 49 - Max: 51 Generation 994 - Average: 49 - Max: 51 Generation 995 - Average: 49 - Max: 50 Generation 996 - Average: 49 - Max: 50 Generation 997 - Average: 48 - Max: 50 Generation 998 - Average: 48 - Max: 50 Generation 999 - Average: 48 - Max: 50 Generation 1000 - Average: 48 - Max: 50
The average fitness of the population increases from 32 initially to 48 by the 1,000th generation, just as you’d expect for a population slowly becoming more fit over time.
If this interests you, I encourage you to try it yourself and experiment with different values for MUTATION_RATE, POPULATION_SIZE, and NUM_BITS.
For example, increasing the mutation rate from 0.001 (1 in 1,000) to 0.01 (1 in 100) has the following effect on the average fitness over time:
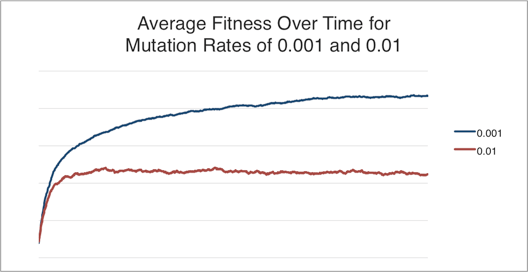
Given the impact that the mutation rate has on long term fitness of the population, how can we determine what the optimal mutation rate is? Can the chromosome’s mutation rate change over time? Can different sections of the chromosome evolve to have different mutation rates? What about the number of bits or the population size? These are a few of the things I hope to find out :)





