Hey friends, it’s been a few weeks since my last update. We had some family visiting one of the Fridays, but otherwise I’ve just been heads down trying to ship a few big projects before the end of the year. Which brings me to…
What I’m working on at Preceden
I’ve got two big projects going on in parallel: a large site redesign and introducing recurring plans to Preceden.
To recap the site redesign: I hired two contractors, one to create mockups iterating on the current design, and a front-end developer to help implement that work and move Preceden over to Tailwind in the process.
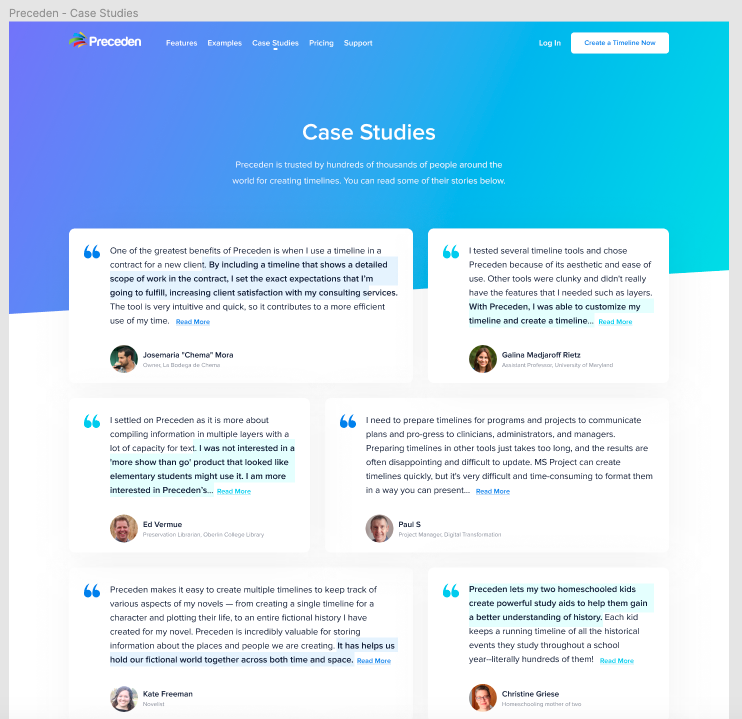
The redesign is shaping up really nicely. Here for example is the above the fold content for the current homepage:
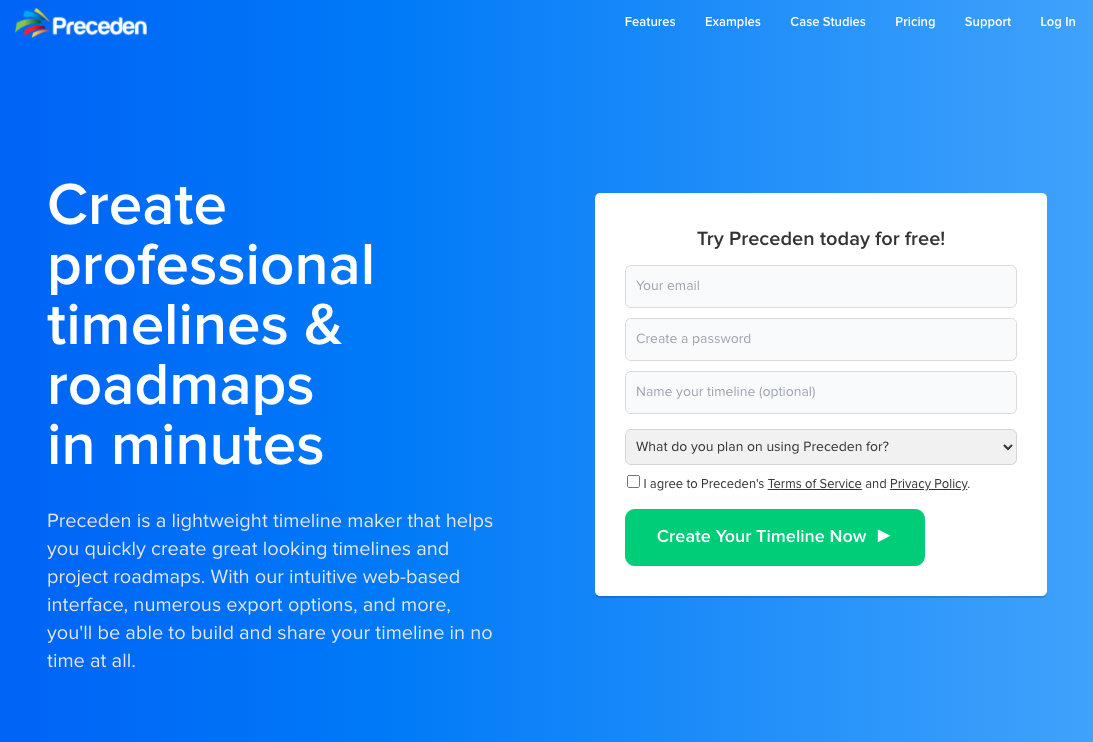
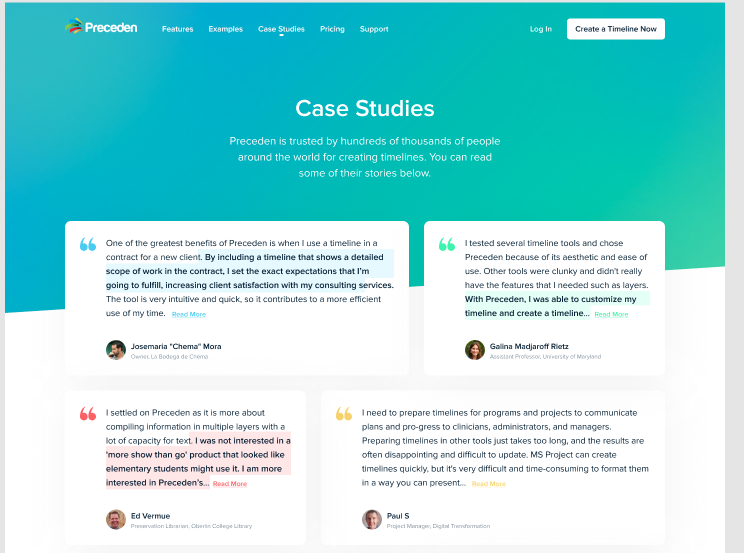
And here’s what it’s going to look like after the redesign:
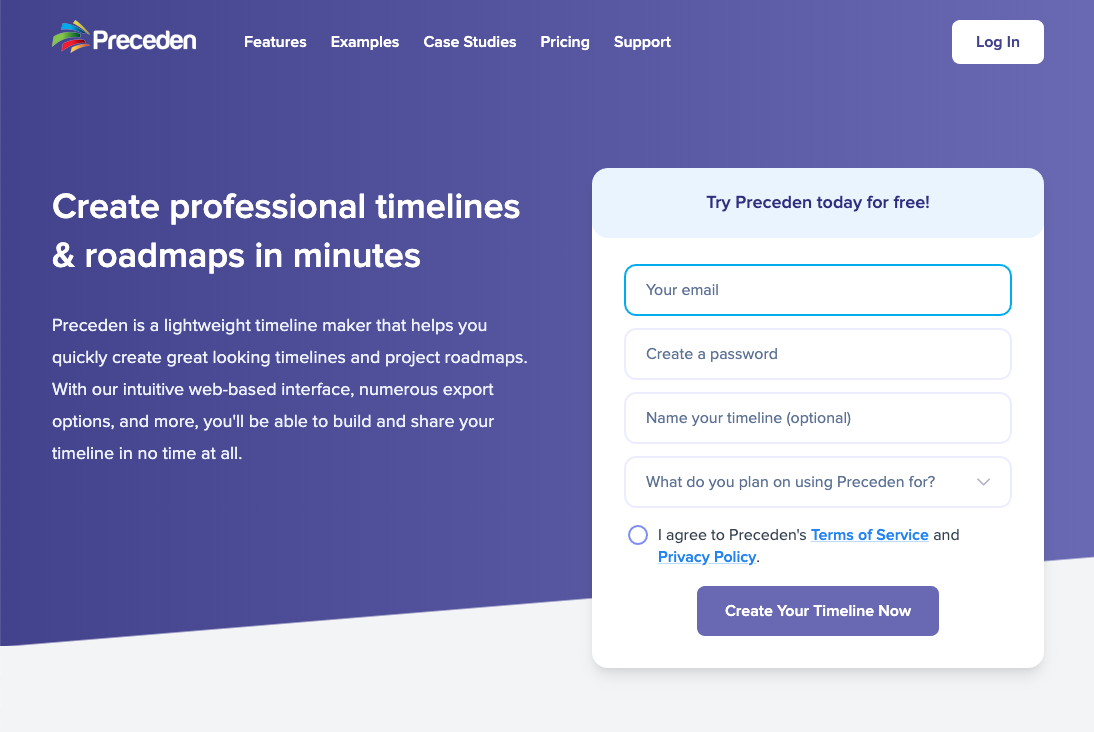
100% of this new design is done in Tailwind too, which has resulted in a massive cleanup of the stylesheets.
In a separate branch, I completely updated Preceden’s billing system, moving from a v1 version of the Stripe API from circa 2012 to the current v3, and used it to introduce recurring plans. Currently Preceden lets you pay for a year, but if you want to keep using it beyond a year, you have to enter your credit card info again. With these new plans, everyone will renew automatically by default, but I’ll of course let them cancel any time and still use it for the full year they paid for. This should hopefully result in a lot more recurring revenue in the future. The big risk is that users will be turned off by the recurring plans and won’t covert from free to paid at the same rate, which could wind up being a net loss even with more recurring revenue down the road.
Here are the current plans:

And here are the revised ones which I’ll ship before end of the year:
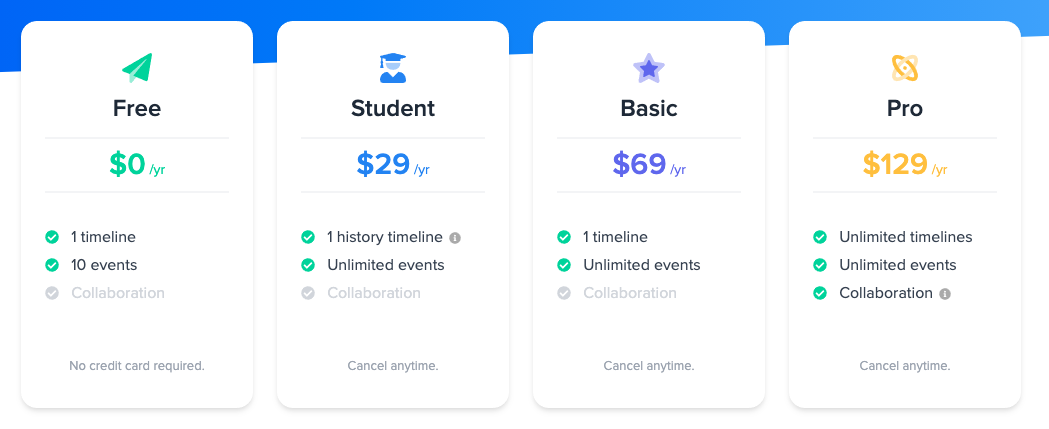
Together these two updates have the potential to have a big positive impact on the business. Fingers crossed it works out that way.
What I’m working on at Help Scout
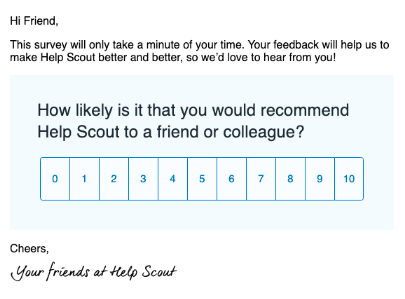
In the past I’ve done a lot of 1:1 Looker training with people at the company, but that’s not going to scale super well as the company grows. To remedy that, I’m going to record a bunch of 3-5 minute training videos on various topics that people can watch at their own convenience. Looker does have training videos that people can watch, but I think it’s a lot more useful for people to be trained on our specific Looker instance so that can learn the ins and outs of our folders, data, etc.
This week had me figuring out how to use Camtasia and Wistia to record and share the first video about navigating Looker, which I then embedded in Slab, the knowledge base tool Help Scout uses internally. Here’s what the video winds up looking like in Slab:

Hoping to record a lot more of these in the coming weeks and months.
What I’m watching
I mentioned to my 6-year old that someone is building a clock to last 10,000 years and he was fascinated by that idea so we’ve been watching YouTube videos about the effort:
It kind of ties in with Preceden too (thinking about long term time horizons).
What I’m reading
Finished book 2 in the John Carter Mars series, The Gods of Mars:

And am now onto book 3, The Warlord of Mars:

I haven’t read a ton of fiction in the past, but am enjoying these and find they’re a good way to wind down before trying to sleep at night.
Hope everyone’s going well with you all. Stay safe 👋.