At the beginning of 2023 I went full time on Preceden, my SaaS timeline maker business, after 13 years of working on it on the side. A year has passed, so I wanted to share an update on how things are going and some lessons learned.
Preceden
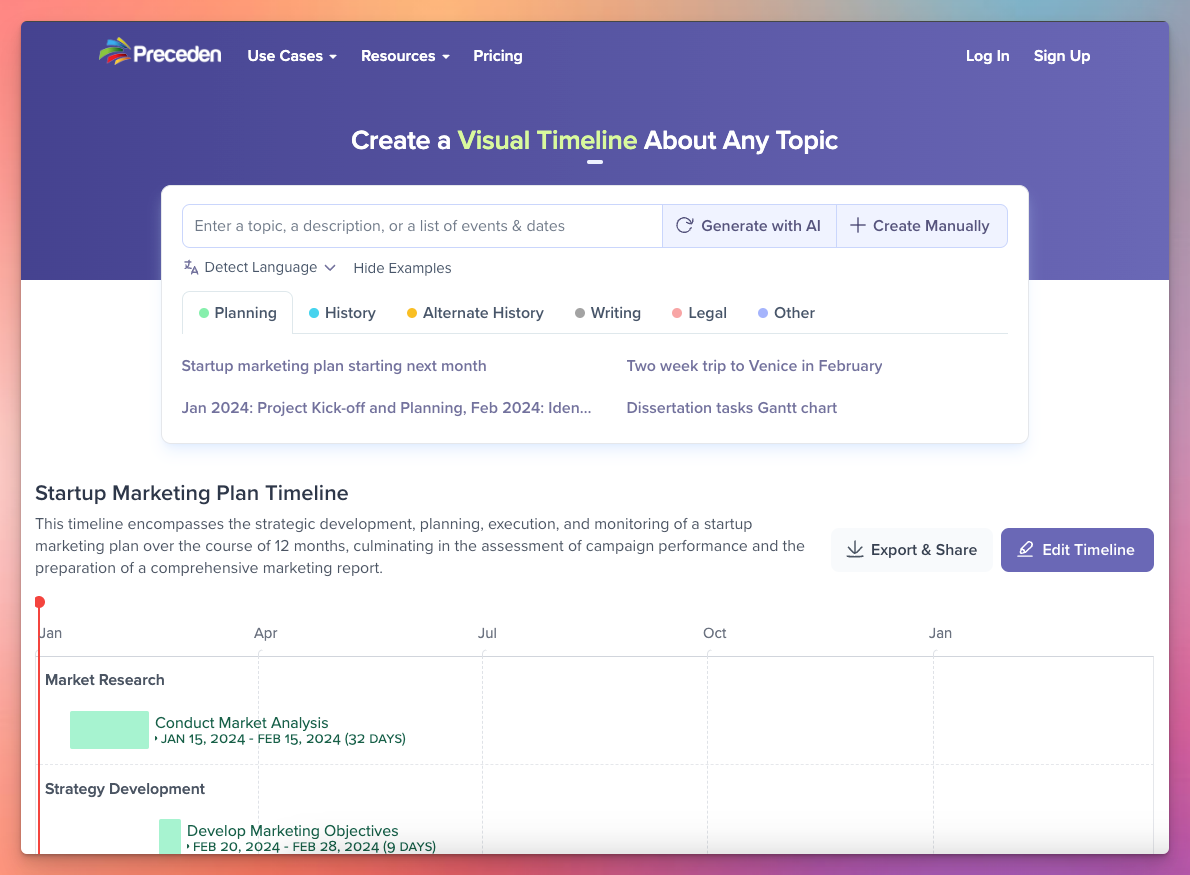
My main focus in 2023 was building AI capabilities into Preceden to make it easier for users to create timelines. For some context: historically people would have to sign up for an account and then manually build their timeline, adding events to it one at a time. For some types of timelines where the events are unique and only known to the user (like a timeline about a legal case or a project plan), that’s still necessary. But for many other use cases (like historical timelines), Preceden can now generate comprehensive timelines for users in less than a minute, for free, directly from the homepage.
It took a good chunk of the year to get that tool to where it is today, starting in February with the launch of a tool for logged-in users to generate suggested events for their existing timelines which laid the groundwork for the launch of the logged-out homepage timeline generator in May. The v1 of that tool was slow and buggy and had design issues and I still hadn’t figured out how to integrate it into Preceden’s pricing model, but a few more months of work got most of those issues ironed out.
Since the launch of that tool in late May, people have generated more than 80k timelines with it, and around a third of new users are signing up to edit an AI generated timeline vs create one from scratch. I’m quite happy with how it turned out, and it’s miles ahead of the competition.
Marketing wise, I didn’t do enough (as usual) but did spend a few weeks working on creating a directory of high quality AI generated timelines about historical topics, some of which are starting to rank well. I also threw a few thousand dollars at advertising on Reddit, though there weren’t enough conversions to justify keeping it up.
I also executed a pricing increase for about 400 legacy customers, which I’ll see the results of this year. More on the results of that and the controversy around it in a future blog post.
Business wise, Preceden makes money in two ways: premium SaaS plans and ads. In 2023, revenue from the SaaS side of the business grew 23% YoY and revenue from the ad side of the business grew 33% YoY. The ad revenue is highly volatile though due to some swingy Google rankings, and will likely mostly disappear in 2024. Still, the SaaS revenue is the main business, and I’ll take 23% YoY growth for a 14 year old business, especially in a year where many SaaS companies struggled to grow.
Emergent Mind
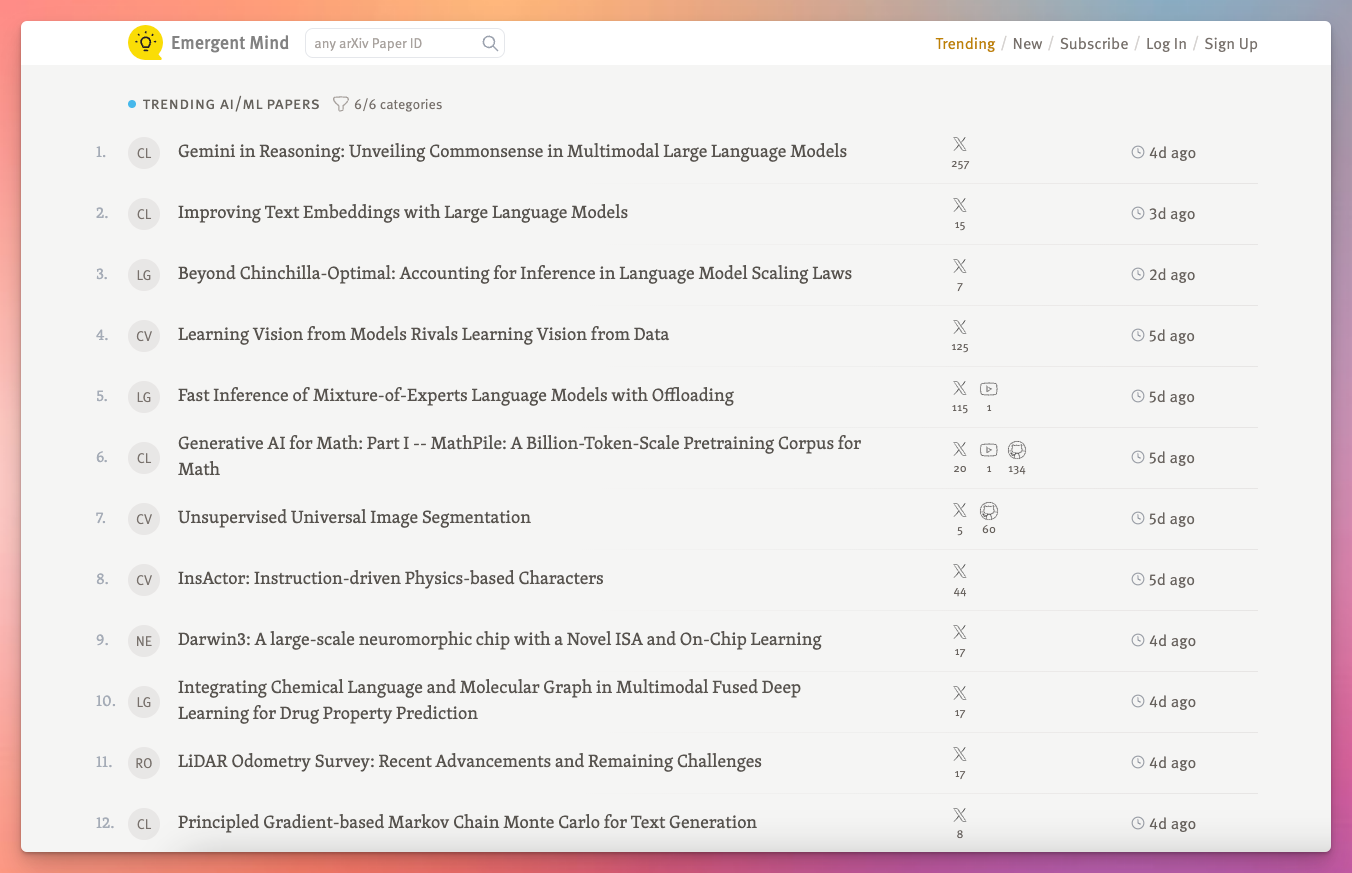
Where to begin? :)
Shortly after ChatGPT launched in late 2022, I launched LearnGPT, a site for sharing ChatGPT examples. The site gained some traction and was even featured in a GPT tutorial on YouTube by Andrej Karpathy. But, a hundred competitors quickly popped up, and my interest in continuing to build a ChatGPT examples site waned, so I decided to shut it down. But then I got some interest from people to buy it, so I put it up for sale, got a $7k offer, but turned it down, and then rebranded the site to Emergent Mind and switched the focus to AI news. A few months into that iteration, I lost interest again (AI news competition is also fierce, and I didn’t think Emergent Mind was competitive, despite some people really liking it), so tried selling it again. I didn’t get any high enough offers, so decided to shut it down, but then decided to keep it, even though I didn’t know what I’d do with it.
And guess what: in November I had an idea for another iteration of the site, this time pivoting away from AI news and into a resource for staying informed about AI/ML research. I worked on that for a good chunk of November/December, and am currently mostly focused on it 😅.
I’m cautiously optimistic about this direction though: the handful of people that I’ve shared it with have been very enthusiastic about it and provided lots of great feedback that I’ve been working through.
Unlike my previous product launches, I’m saving a HN/Reddit/X launch announcement for later, after I’ve gotten the product in really good shape. There’s still lots of issues and areas for improvement, and I believe now it’s a better route to soft launch and iterate on it quietly based on 1:1 feedback before drawing too much attention to an unpolished product. Hat-tip Hiten Shah for influencing how I think about MVPs.
I’ll add too that this “surfacing trending AI/ML research” direction is the first step in a larger vision I have for the site. I think it could evolve into something really neat – maybe even a business – though time will tell.
2024
Preceden is in a good/interesting spot where it’s a fairly feature-complete product that requires very little support and maintenance. I don’t have any employees, and could not work on it for months and it would likely still grow and continue to work fine.
When I look ahead, the most popular feature requests seem like they won’t be heavily used and will wind up bloating the product and codebase. That doesn’t mean there’s no room for improvement – there always is – just that I’m not sure it makes sense anymore for me to be so heads down in VS Code working on it. It’s the first time maybe ever that I’ve thought that. I’d probably see more business impact by spending my time on marketing, but that’s not exactly what I want to spend a lot of my time doing, plus I also can’t afford the kind of talent I’d need to market it effectively either (marketing a B2C horizontal SaaS isn’t fun).
So, my current thinking is that I’ll keep improving and lightly marketing Preceden, but with less intensity than I have in years past. Instead, I’ll devote more of my time to building other products: Emergent Mind and maybe others in the future. Maybe one of those will turn into a second income stream but maybe not. I enjoy the 0 to 1 aspect of creating new products, and the income from Preceden supports me in pursuing that for now. And if Preceden starts declining, I can always start focusing on it again, or go back to contracting or a full time position somewhere, which isn’t a bad outcome either.
Also, one thing I regret not doing more of in 2023 was spending more time wandering. It’s easy for me to get super focused on some project and not leave any time in my day for exploring what else is out there. Only toward the end of the year did I start experimenting with new AI tech like Mixtral. Going forward, I want to spend some time each week learning about, experimenting with, and blogging about new AI tech. I’m still very much in the “AI will change the world in the coming years” camp, and I have the freedom and interest to spend some of my time learning and tinkering, so am going to try to do that.
As always, I welcome any feedback on how I’m thinking about things.
Happy new year everyone and thanks for reading 👋.