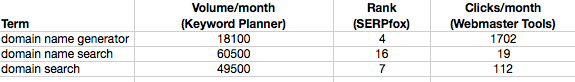When it comes to naming your analytics events, consistency is key.
For example, if you name one event “Signed In” (titleized, spaces, past tense), then name your signed-out event “Signed Out” not “signed out”, “Sign Out”, “signed_out”, “signOut”, etc.
Ideally you should decide on naming conventions before you start tracking any events. The reason is that once you start tracking an event under one name, most analytics services won’t let you rename it. You can rename the event you send the analytics service, but then you wind up losing the historical trends with the old name. Because of this, normally you’ll wind up sticking with the original name even if you later wish you could change it.
If you can, wrap the analytics event API call with your own validation logic to ensure that everyone is forced to use the same conventions. Also, create solid documentation so there’s a resource for new developers to learn best practices.
At Automattic we have our own internal analytics service called Tracks. Here’s a summary of the guidelines we provide our developers for event naming conventions:
- Use lowercase letters.
- Numbers are allowed.
- Separate words with underscores.
- Don’t abbreviate unnecessarilly.
- Don’t programmatically create event names; hardcode them all. This prevents developers from accidentally flooding our analytics tools with thousands of event names. It also makes the event names easily searchable in our codebase.
- For page loads, use “view”, not “visit”, “load”, etc.
- Use present tense for verbs (why used “signed_out” when the shorter”sign_out” will do?). In practice most developers forget this so we don’t enforce it.
We also format our event names so that the source (Calypso, Akismet, etc) is first, the context is second, and the verb is at the end. This makes them appear next to each other in alphabetized event lists in our tools. For example:
akismet_product_purchase
akismet_product_refund
calypso_product_purchase
calypso_product_refund
There is an argument to be made for having a single product_purchase event and passing a property such as source that is set to akismet, calypso, etc but we generally don’t do that because a) Putting the source first lets us partition the databases based on it to make querying for events faster and b) In many cases even though the event is conceptually similar, they wind up varying a lot in the properties attached to them. For example, maybe on one service users buy plans and another service they buy upgrades. If both services share the same event name, you would probably want to ensure a consistent property name that represents what the user purchased. Do you use plan, upgrade or something more generic? To keep things simple, we simply use similar event names but prefix them with their source (ie, akismet_product_purchase and calypso_product_purchase).
We also enforce that property names use similar formatting conventions (lowercase, letters only, snake case).
I hope this gives you some things to think about next time you’re setting up tracking for your apps.
If you have any best practices at your company for naming events, I’d love to learn how you all go about it.