One of Preceden’s most popular feature requests over the years has been the ability to upload images to Preceden and have those images appear on timelines.
A lot of competitors offer that functionality, but I procrastinated for almost 9 years for two reasons:
It’s complex to implement, both in terms of actually handling the uploads and having them appear on the timelines.
Most of the people that requested it were using Preceden for school timelines and that segment of users tend not to upgrade at a high rate. People using Preceden for work-related project planning timelines didn’t request it much. Therefore, it never was much of a priority because it likely wouldn’t move the needle on the business.
That said, since I’ve had more time to work on Preceden recently, I decided to finally do it. For handling uploads, I wound up using Filestack.com which simplified the implementation a lot. And updating Preceden’s rendering logic took time too, but in the end it all worked out.
The most common feature request I get for Preceden is to make it possible to add images to timelines. With today's update, folks can now do just that 🎉. Here's the before and after of a student's timeline about the best movies. pic.twitter.com/QDyNaO89NY
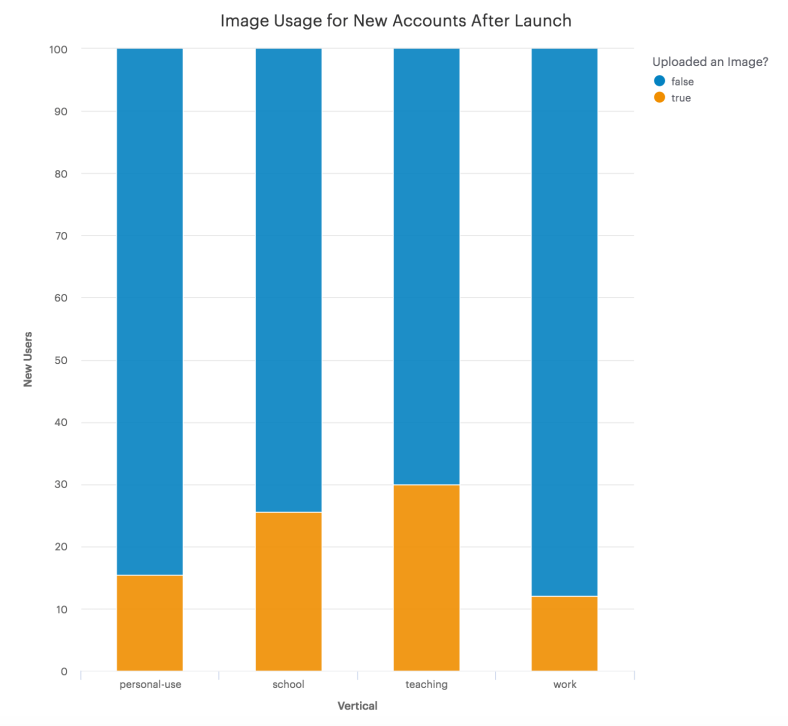
I recently checked on the usage stats and – not surprisingly – it’s used most heavily by people using Preceden for education:
For users that have signed up since this launched:
Teaching: 29% uploaded an image
School: 26%
Personal Use: 16%
Work: 12%
In other words, it’s used very heavily (which is great!) but not with the segment of users with the highest propensity to pay.
This dilemma comes up fairly often: do you build Feature A that will be used heavily by mostly-free users, or Feature B that will be used heavily by mostly-paying customers?
For better or worse, I never wound up focusing on one market or use case with Preceden: it’s a general purpose timeline maker that can be used for any type of timeline. As a result though, I often get into these situations. If I was just building Preceden for project planners, I’d never implement image uploads. If I was just building it for students creating timelines for school, I’d probably have implemented it years ago.
It also comes down to goals: if my main goal is growing revenue, I probably shouldn’t work on features like this. But if I want Preceden to be the best general purpose timeline maker then it does, but there’s an opportunity cost because I’m not building features for the folks who will actually pay.
I operate in the middle for product development: work mostly on features that will make money, but also spend some percentage of my time on features like this that will make it a better general purpose tool.
If I were to start something from scratch today, I’d probably pick a narrow niche and try to nail it. No general-purpose tools. I’d recommend that to others too.
Going broad is fun in a way too though, it just has it’s challenges :).
At Help Scout, we recently went through the process of hiring a new senior data analyst. In order to apply for the position, we asked anyone interested to answer a few short screener questions including one to help evaluate their SQL skills.
Here’s the SQL screener question we asked. If you’re an analyst, you’ll get the most value out of this post if you work through it before reading on:
We’re currently in the process of rolling out Beacon, our live chat tool, to existing customers who have expressed interest trying it.
Customers could have expressed interest in two ways: either by filling out an interest form or mentioning to our support team that they want to try it.
For the interest form, there is one table, hubspot.contact, with two relevant fields:
email – The user’s email address
property_beacon_interest – A Unix timestamp in milliseconds representing when they filled out the form or null if they have not expressed interest
When a customer expresses interest in a support conversation, our support team tags the conversation with a beacon-interest tag. There are two relevant tables:
helpscout.conversation with three relevant fields:
id – The id of the conversation
email – The email of the person who reached out to support
created_at – A timestamp with the date/time the conversation was created
+----+-------------------+--------------------------+
| id | email | created_at |
+----+-------------------+--------------------------+
| 1 | matt@example.com | 2018-08-14 14:02:10 UTC |
| 2 | eli@example.com | 2018-08-14 14:06:30 UTC |
| 3 | matt@example.com | 2018-08-14 14:07:33 UTC |
| 4 | katia@example.com | 2018-08-14 14:11:30 UTC |
| 5 | jen@example.com | 2018-08-13 14:11:30 UTC |
+----+-------------------+--------------------------+
There’s also a helpscout.conversation_tag table with two relevant fields:
conversation_id – The id of the conversation that was tagged. A conversation can have zero or more tags.
Write a SQL query (any dialect is fine) that combines data from these two sources that lists everyone who has expressed interest in trying Beacon and when they first expressed that interest.
The end result using the example tables above should be a functioning SQL query that returns the following:
+-------------------+-------------------------+
| email | expressed_interest_at |
+-------------------+-------------------------+
| matt@example.com | 2018-08-12 19:16:17 UTC |
| eli@example.com | 2018-08-14 14:06:30 UTC |
| katia@example.com | 2018-08-14 14:11:30 UTC |
+-------------------+-------------------------+
You should include your query in the response field to this question in the online application.
This question – designed to be answered in 10-15 minutes – proved incredibly valuable because it served as an easy way to evaluate whether applicants had the minimum technical skills to be effective in this role. This position requires working a lot with SQL, so if an applicant struggled with an intermediate SQL challenge, they would likely struggle in the role as well.
What surprised me is that almost none of the answers were identical, except for a few towards the end because someone commented on the Gist with a (slightly buggy) solution :).
For reference, here’s how I would answer the question:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
There are a lot of variations on this though that will still result in the correct answer – and many which won’t. For example, no points lost for using uppercase SQL instead of lowercase. But if the query doesn’t union the tables together at some point, it probably wouldn’t result in the correct answer.
If you’re interested in data analysis and analytics, you can subscribe to my Matt on Analytics newsletter to get notified about future posts like this one.
Analyzing the Differences
It would be impossible to list every difference – as you’ll see at the end of this post in the anonymized responses, there are and endless number of ways to format the query.
That said, there are a lot of common differences, some substantial, some not.
SQL Casing
Does the query use uppercase or lowercase SQL or some combination of the two?
Note that in these examples and all that follow, the answers aren’t necessarily correct. They’re just chosen to highlight different ways of approaching the query.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Common Table Expressions go a long way towards making your query easy to read and debug. Not all SQL dialects support CTEs (MySQL doesn’t, for example), but using them in the query was almost always an indicator of an experienced analyst.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
CTEs benefit a lot from meaningful names that make it easy for you and other analysts to interpret.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
“INNER” is implied if you just write “JOIN”, so it’s not required, but can make the query easier to read. Either way is fine.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The standard way to filter the conversations is to use a WHERE clause to filter the results to only include those that have a beacon-interest tag. However, because we’re using an INNER JOIN, it’s also possible to add it as a join condition and get the same result. In terms of performance, it doesn’t make a difference which approach you take.
I lean towards a WHERE clauses because I think it’s clearer, but including it in the JOIN condition is completely viable as well.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
HubSpot stores the form submission timestamp in milliseconds. Queries that didn’t account that would not result in the correct result.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
There are two types of UNIONs: UNION DISTINCT and UNION ALL. The former – which is the default when you just write UNION – only returns the unique records in the combined results.
Both result in the correct answer here, but UNION ALL performs better because with UNION DISTINCT the database has to sort the results and remove the duplicate rows.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Many applicants didn’t take into account that people could have expressed interest by filling out the HubSpot form and contacting support. Neglecting to account for this could result in multiple rows for individual email addresses.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
I lean towards using column numbers, but either is fine, and using the column name can have benefits. When there are 5+ columns (which is not an issue with this question), lean towards using column numbers which will be a lot more sane than typing out all the names (hat-tip Ray Buhr for this tip).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Single vs Multiple Lines When Listing Multiple Columns
Another common style difference is whether people put multiple columns on the same line or not. Either is fine, but I lean towards one column per line because I think it’s easier to read.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
While not that common in the responses, it’s perfectly valid when listing columns on multiple lines to put the commas before the column name. The benefit is that you don’t have to add a comma to the previous line when adding a new column which also simplifies query diffs that you might see in your version control tool.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Comma-first folks tended to have software development backgrounds.
PS: For anyone interested in SQL coding conventions, I highly recommend checking out dbt’s coding conventions which have influenced my preferences here.
All Responses
We were fortunate to receive over 100 applications, most of which included an answer to the SQL question. I suspect if the application didn’t include this question, we would have had twice the number of applcants, but the presence of this question led some underqualified folks not to apply.