Unlike many indie founders, I’ve never shared revenue numbers for Preceden, my SaaS timeline maker tool. Even if they were remarkable – which they are not really – I just don’t think there are many good reasons to publicly share revenue numbers, and there are lots of downsides.
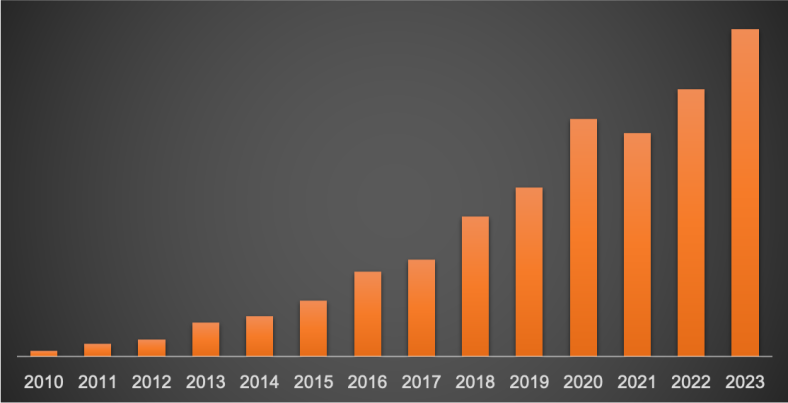
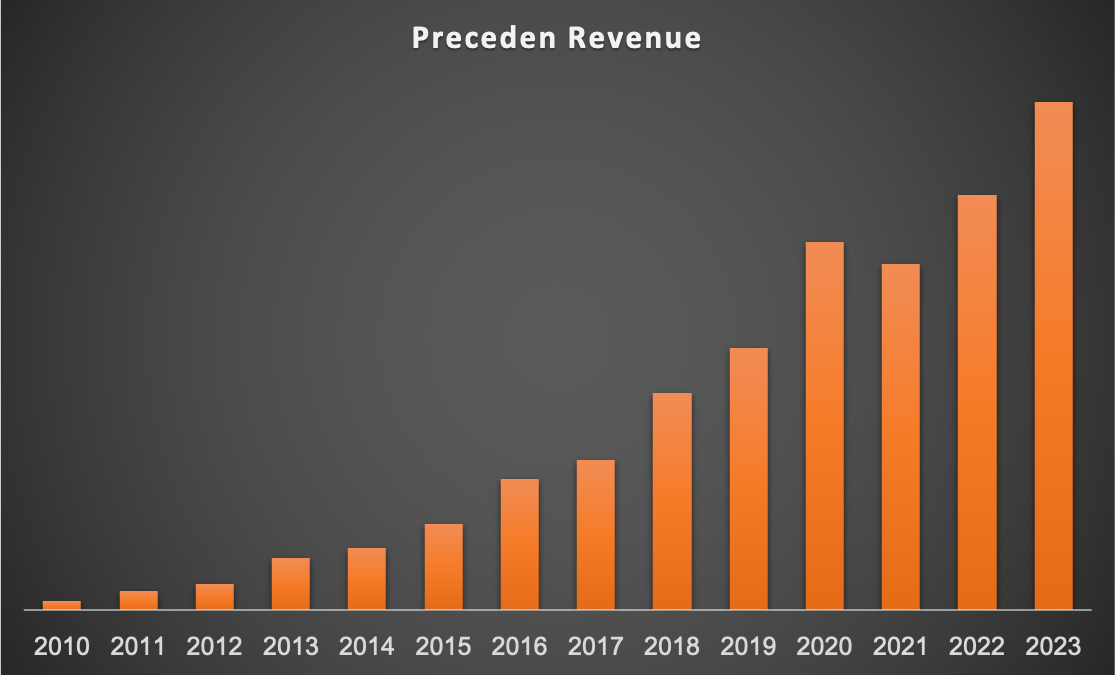
However, below I’ll share a chart showing Preceden’s yearly revenue (though omitting actual numbers), because I think there are some lessons there and it may serve as inspiration for other indie founders.
Check this out:
Some thoughts…
I started Preceden as a side project in late 2009 when I was 24 and still a lieutenant in the Air Force. I knew I didn’t want to make the Air Force a career, so began learning web development in my spare time, and Preceden was one of the first products I launched. I only went full time on it at the beginning of 2023, a milestone I wrote about in this blog post.
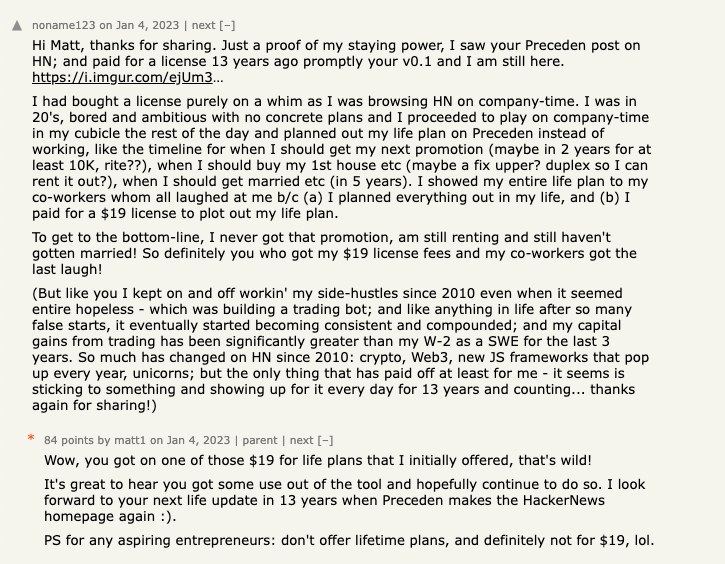
When I started Preceden, I really had no idea what I was doing. I was an entrepreneurial amateur web developer with little experience building, marketing, or growing a business. For example, Preceden was entirely free for several months after launch, then I introduced a $19-for-life PayPal-only payment option, as recalled by this HackerNews user:
Payments started trickling in though. It didn’t make much money that first year, but over time, I got a bit savvier thanks to conferences like Microconf and slowly – very slowly – turned it into a better business.
There were years early on where I put it on the back-burner to work on other products. Most of those were duds, but one, Lean Domain Search, was acquired by Automattic after I got out of the Air Force, which is how I landed a software engineering (“code wrangler”) job there.
While I was at Automattic, I still had Preceden running on the side. Early on, revenue was nowhere near enough to even consider leaving Automattic to go full time on it and honestly I didn’t even want to. I enjoyed the work I was doing there and was learning a ton.
But, I could work on Preceden here and there on nights and weekends (at least before I had kids), and I could do some math to see that if I could grow it at X%/year, then down the road it could grow to the point where it would give me the option to go full time on it.
And so that’s what I did: kept it as side project while at Automattic and later when I went to go work at Help Scout. At both companies, I sought out opportunities to work with different teams so I could get more exposure to the marketing and the business sides of the companies, knowing that they would get smarter about growing my own business.
And each year, Preceden’s revenue grew. Looking at the history of the business, the compounded annual growth rate is 37%. That’s a decent growth rate for a business earning lots of money, but that wasn’t the case for most of Preceden’s existence: imagine making $5k one year and growing 37%ish to $7k. Not great, but… then that $7k grows to $9.6k, then $13k, and so on, and eventually those jumps start becoming meaningful.
For most of Preceden’s history, it was not a proper SaaS business with recurring revenue. For the first few years, it was all lifetime deals: pay $29 or similar and you can use Preceden forever (the nature of the product back then was that most people didn’t use it long term, so I offered plans that reflected that). Eventually I put a 1-year limit on it, so customers would have to manually pay again if they wanted to keep using it each year. A few years ago, I switched it to standard automatically-recurring SaaS pricing and that has certainly helped with revenue growth.
One thing I realized years into it is that Preceden wasn’t a great business to start in the first place. It’s mostly B2C (people creating history timelines and for personal projects, though some B2B for people using it for project planning) and the nature of it is that most customers don’t need to use it that long and don’t want to pay a lot for it. Combine that with me starting as an inexperienced entrepreneur working on it as a side project, and you’ve got a recipe for a very difficult business to grow. (I’ll add though if I had been savvier, I wouldn’t have started it, but it did work out in the long run, so maybe my inexperience was somewhat of an advantage.)
It’s interesting to me though if you look at that revenue chart, there’s fairly consistent growth through most of Preceden’s history, even though it didn’t have automatically recurring SaaS revenue until the tail end of it. (One exception being 2020 which saw abnormally strong growth due to lots of people moving processes online because of Covid.)
The way I look at it is that every year, I’ve made just enough improvements to the product/marketing/business that they (combined with a small amount of recurring revenue and compounding marketing efforts) all sum up to result in that year-over-year growth.
There have been very few big, immediate jumps in revenue. Mostly just lots of slowly improving every aspect of the business, as you can get a sense of from the commit count and dates from the Preceden repo:
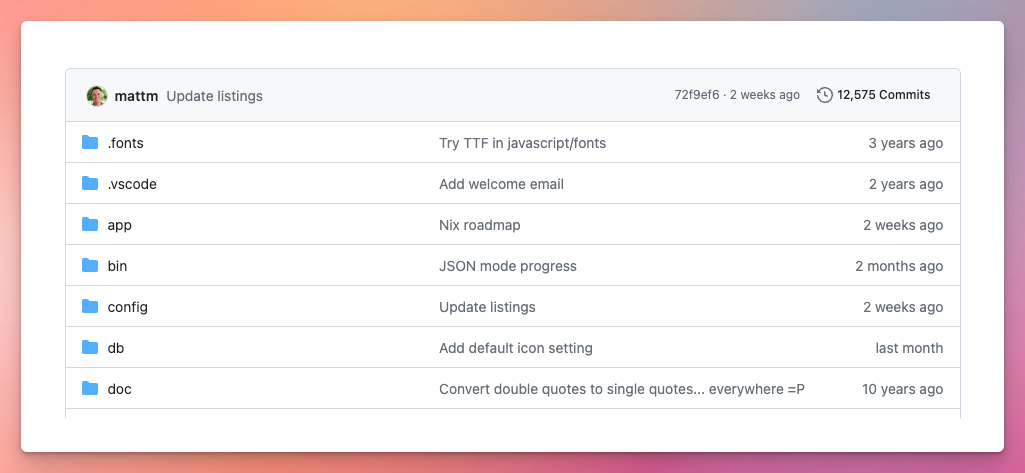
For any indie founders out there who have not seen hockey stick growth for their product, I hope this serves as some evidence that it is possible (and perfectly fine!) to slowly grow your side project over many years.
If you can maintain slow but consistent revenue growth year after year, it should eventually grow into a meaningful amount of revenue and give you options down the road, whether it be to go full time on it, or use it to support yourself while pursuing other projects (like I am now with Emergent Mind, a resource for staying informed about important new AI/ML research), or something else entirely. And even if you never go full time on it, the lessons you’ll learn trying to grow your business will make you a much more valuable employee and help you grow your salary, which is a great outcome as well.
Drop me a note if you’re on a similar journey, I’d love to say hey: matthew.h.mazur@gmail.com.