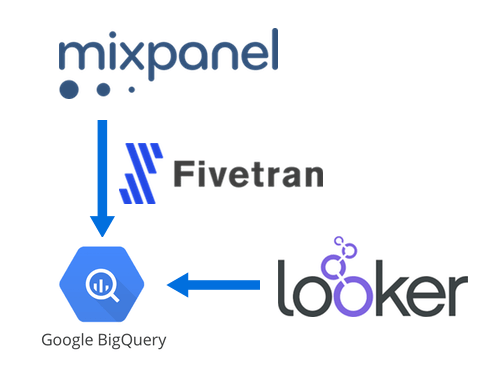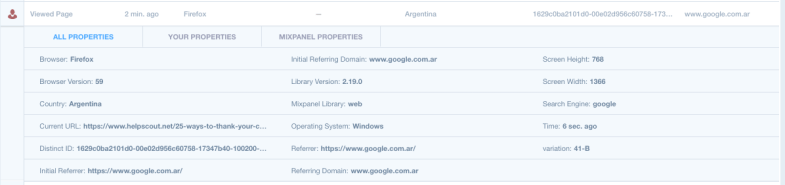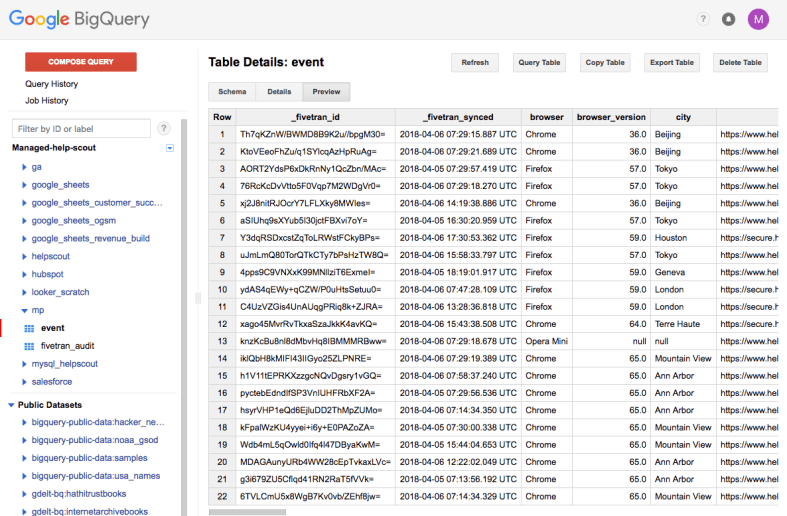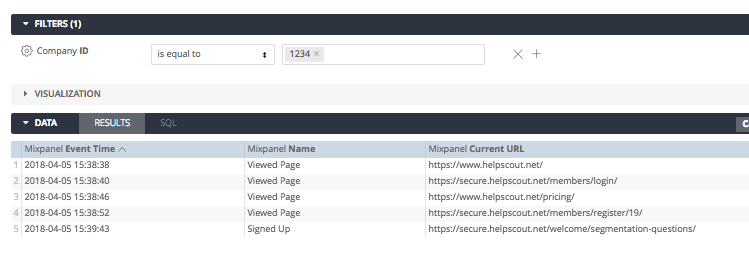
In a recent post I outlined how to use Fivetran to sync Mixpanel data to BigQuery for analysis in Looker. Today we’ll walk through how to write a SQL query to analyze a funnel using the Mixpanel data in BigQuery.
For this analysis, we’re going to create a three-step funnel showing how many visitors who start on Help Scout’s pricing page click through to the sign up page and then sign up.
One Step
To begin, lets just look at visitors who viewed the pricing page:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| distinct_id, | |
| time AS viewed_pricing_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://www.helpscout.net/pricing/%" | |
| +—————————————————-+——————————–+ | |
| | distinct_id | viewed_pricing_at | | |
| +—————————————————-+——————————–+ | |
| | 1628dfc9f7e0-0184dcc4e-71615c5a-49a10-1628dfc9f800 | 2018-04-03 17:09:27.000000 UTC | | |
| | 16291bd96456-01abc2a0f-87a6c72-2c880-16291bd9648ae | 2018-04-04 10:41:32.000000 UTC | | |
| | 162936a4e6f37-01526b61-6b4b327d-25800-162936a4e738 | 2018-04-04 18:27:46.000000 UTC | | |
| | 162a0381d481-0b3137c58-60031d3c-3d10d-162a0381d496 | 2018-04-07 06:10:35.000000 UTC | | |
| +—————————————————-+——————————–+ |
You might wonder why we need the % at the end of the URL; that’s simply to make sure the results include pages with URL parameters such as https://www.helpscout.net/pricing/?utm_source=adwords.
Two Steps
Next, we’ll join these results on sign up page data, making sure that the sign up page views occurred after the pricing page views:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| pricing.distinct_id, | |
| viewed_pricing_at, | |
| viewed_sign_up_at | |
| FROM ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_pricing_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://www.helpscout.net/pricing/%" | |
| ) pricing | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_sign_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://secure.helpscout.net/members/register/%" | |
| ) sign_up_page ON sign_up_page.distinct_id = pricing.distinct_id AND sign_up_page.viewed_sign_up_at > viewed_pricing_at | |
| +———————————————————–+——————————–+——————————–+ | |
| | distinct_id | viewed_pricing_at | viewed_sign_up_at | | |
| +———————————————————–+——————————–+——————————–+ | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:31:26.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-05 12:48:37.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:28:42.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:27:49.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:35:51.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | |
| | 162914788c5fb-09337b4c437dc4-b34356b-144000-162914788c628 | 2018-04-04 17:30:18.000000 UTC | | | |
| +———————————————————–+——————————–+——————————–+ |
The reason we LEFT JOIN is because not all visitors will make it to the next step of the funnel and we want the data to reflect that.
Note that we join on both the distinct_id (to ensure each result is for a single visitor) and on the time the events occurred.
Three Steps
Extending this to the third and final step of the funnel, the Signed Up event, we get:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| pricing.distinct_id, | |
| viewed_pricing_at, | |
| viewed_sign_up_at, | |
| signed_up_at | |
| FROM ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_pricing_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://www.helpscout.net/pricing/%" | |
| ) pricing | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_sign_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://secure.helpscout.net/members/register/%" | |
| ) sign_up_page ON sign_up_page.distinct_id = pricing.distinct_id AND sign_up_page.viewed_sign_up_at > viewed_pricing_at | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS signed_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Signed Up" | |
| ) signed_up ON signed_up.distinct_id = pricing.distinct_id AND signed_up.signed_up_at > viewed_sign_up_at | |
| +———————————————————–+——————————–+——————————–+——————————–+ | |
| | distinct_id | viewed_pricing_at | viewed_sign_up_at | signed_up_at | | |
| +———————————————————–+——————————–+——————————–+——————————–+ | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:31:26.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-05 12:48:37.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:28:42.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:27:49.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | | |
| | 1628be3f8ab208-0678714f9f0ec-b34356b-1fa400-1628be3f8b825 | 2018-04-03 07:35:51.000000 UTC | 2018-04-09 06:08:08.000000 UTC | | | |
| | 162914788c5fb-09337b4c437dc4-b34356b-144000-162914788c628 | 2018-04-04 17:30:18.000000 UTC | 2018-04-04 17:31:13.000000 UTC | 2018-04-04 17:34:51.000000 UTC | | |
| | 162914788c5fb-09337b4c437dc4-b34356b-144000-162914788c628 | 2018-04-04 08:31:16.000000 UTC | 2018-04-04 17:24:52.000000 UTC | 2018-04-04 17:34:51.000000 UTC | | |
| +———————————————————–+——————————–+——————————–+——————————–+ |
Determining the First Event Occurrence for Each Step
The query above will return every combination of pricing page views, sign up page views, and sign up events for each visitor. For our funnel though, we don’t care whether they loaded the pricing page or sign up page multiple times, we only care that they did it at all. So we modify the query to only return the first instance of each event for each visitor:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| pricing.distinct_id, | |
| MIN(viewed_pricing_at) AS viewed_pricing_at, | |
| MIN(viewed_sign_up_at) AS viewed_sign_up_at, | |
| MIN(signed_up_at) AS signed_up_at | |
| FROM ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_pricing_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://www.helpscout.net/pricing/%" | |
| ) pricing | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_sign_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://secure.helpscout.net/members/register/%" | |
| ) sign_up_page ON sign_up_page.distinct_id = pricing.distinct_id AND sign_up_page.viewed_sign_up_at > viewed_pricing_at | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS signed_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Signed Up" | |
| ) signed_up ON signed_up.distinct_id = pricing.distinct_id AND signed_up.signed_up_at > viewed_sign_up_at | |
| GROUP BY 1 | |
| +————————————————————–+——————————–+——————————–+——————————–+ | |
| | distinct_id | viewed_pricing_at | viewed_sign_up_at | signed_up_at | | |
| +————————————————————–+——————————–+——————————–+——————————–+ | |
| | 162931933729b2-0b3ba365e6d865-336c7b05-384000-1629319337333b | 2018-04-04 16:58:45.000000 UTC | 2018-04-11 20:50:13.000000 UTC | 2018-04-11 20:51:46.000000 UTC | | |
| | 162b770945247a-0145ce1cbf076d8-495860-1fa400-162b77094541286 | 2018-04-11 19:56:18.000000 UTC | 2018-04-11 20:02:54.000000 UTC | | | |
| | 162899a5ec5895-0fc657f6c6ebde-33697b07-384000-162899a5ec68c6 | 2018-04-09 19:20:01.000000 UTC | 2018-04-11 19:38:59.000000 UTC | | | |
| | 162b73858df1f8-0625fc7a476d418-76313118-3d10d-162b73858e2237 | 2018-04-11 17:19:53.000000 UTC | 2018-04-11 17:23:22.000000 UTC | | | |
| | 162b6d32dd11a5-0bbf34346ce939-3553629-231015-162b6d32dd2646 | 2018-04-11 15:30:09.000000 UTC | 2018-04-11 16:40:08.000000 UTC | | | |
| | 162875b83f63e2-0870a441baadb6-33697b07-384000-162875b83f714f | 2018-04-02 10:15:44.000000 UTC | 2018-04-11 14:56:37.000000 UTC | 2018-04-11 14:57:27.000000 UTC | | |
| +————————————————————–+——————————–+——————————–+——————————–+ |
Measuring the Funnel
Finally, we count how many visitors made it to each step to get our funnel:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| COUNT(viewed_pricing_at) AS viewed_pricing, | |
| COUNT(viewed_sign_up_at) AS viewed_sign_up, | |
| COUNT(signed_up_at) AS signed_up | |
| FROM ( | |
| SELECT | |
| pricing.distinct_id, | |
| MIN(viewed_pricing_at) AS viewed_pricing_at, | |
| MIN(viewed_sign_up_at) AS viewed_sign_up_at, | |
| MIN(signed_up_at) AS signed_up_at | |
| FROM ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_pricing_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://www.helpscout.net/pricing/%" | |
| ) pricing | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS viewed_sign_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Viewed Page" AND | |
| current_url LIKE "https://secure.helpscout.net/members/register/%" | |
| ) sign_up_page ON sign_up_page.distinct_id = pricing.distinct_id AND sign_up_page.viewed_sign_up_at > viewed_pricing_at | |
| LEFT JOIN ( | |
| SELECT | |
| distinct_id, | |
| time AS signed_up_at | |
| FROM mp.event | |
| WHERE | |
| name = "Signed Up" | |
| ) signed_up ON signed_up.distinct_id = pricing.distinct_id AND signed_up.signed_up_at > viewed_sign_up_at | |
| GROUP BY 1 | |
| ) visitor_data | |
| +—————-+—————-+———–+ | |
| | viewed_pricing | viewed_sign_up | signed_up | | |
| +—————-+—————-+———–+ | |
| | 1234 | 567 | 89 | | |
| +—————-+—————-+———–+ |
Voila!
From here, you can take it a step further and segment the results on a property in the first step of the funnel or add a funnel duration to limit how long visitors have to complete the funnel, etc.
If you have any questions about this, don’t hesitate to reach out.