Today marks the end of my first week of full-time indie hacking. I feel like I’m getting in a good groove as far as my daily routine, but I don’t think it’s quite sunk in yet how much flexibility I have in terms of my daily schedule. For example, I’m still waking up early to workout and still mostly working 9am-5pm, despite having the flexibility to make my own hours. That said, keeping a normal routine and structuring my workday like a normal job might work best for me. We’ll see.
Preceden
On the Preceden front, I started work on a promising new feature that uses GPT to suggest events to add to your timeline.
For example, imagine you want to create a timeline of World War II. In the past, you would have to research and manually add events to your Preceden timeline to populate it. With this new feature, you can hit a button and it will generate a list of suggestions for World War II or any other topic:
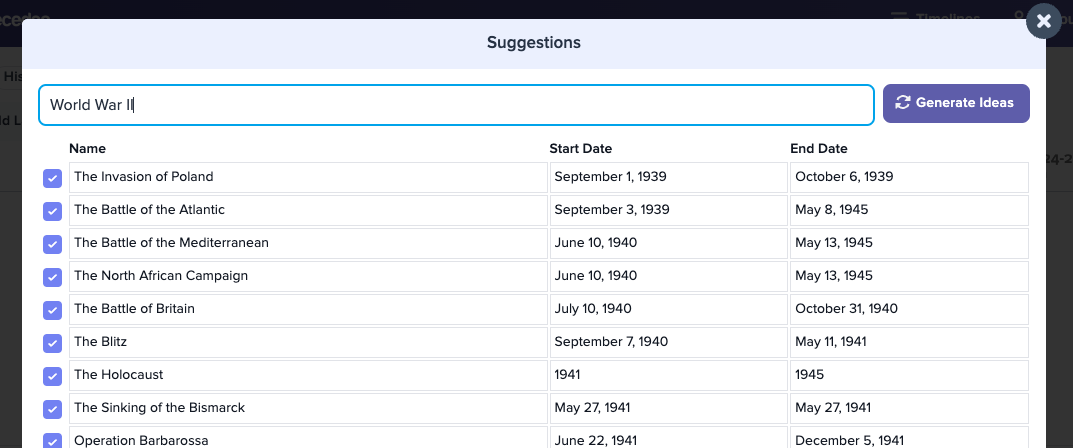
And with the click of another button, you can add those suggestions to your timeline:
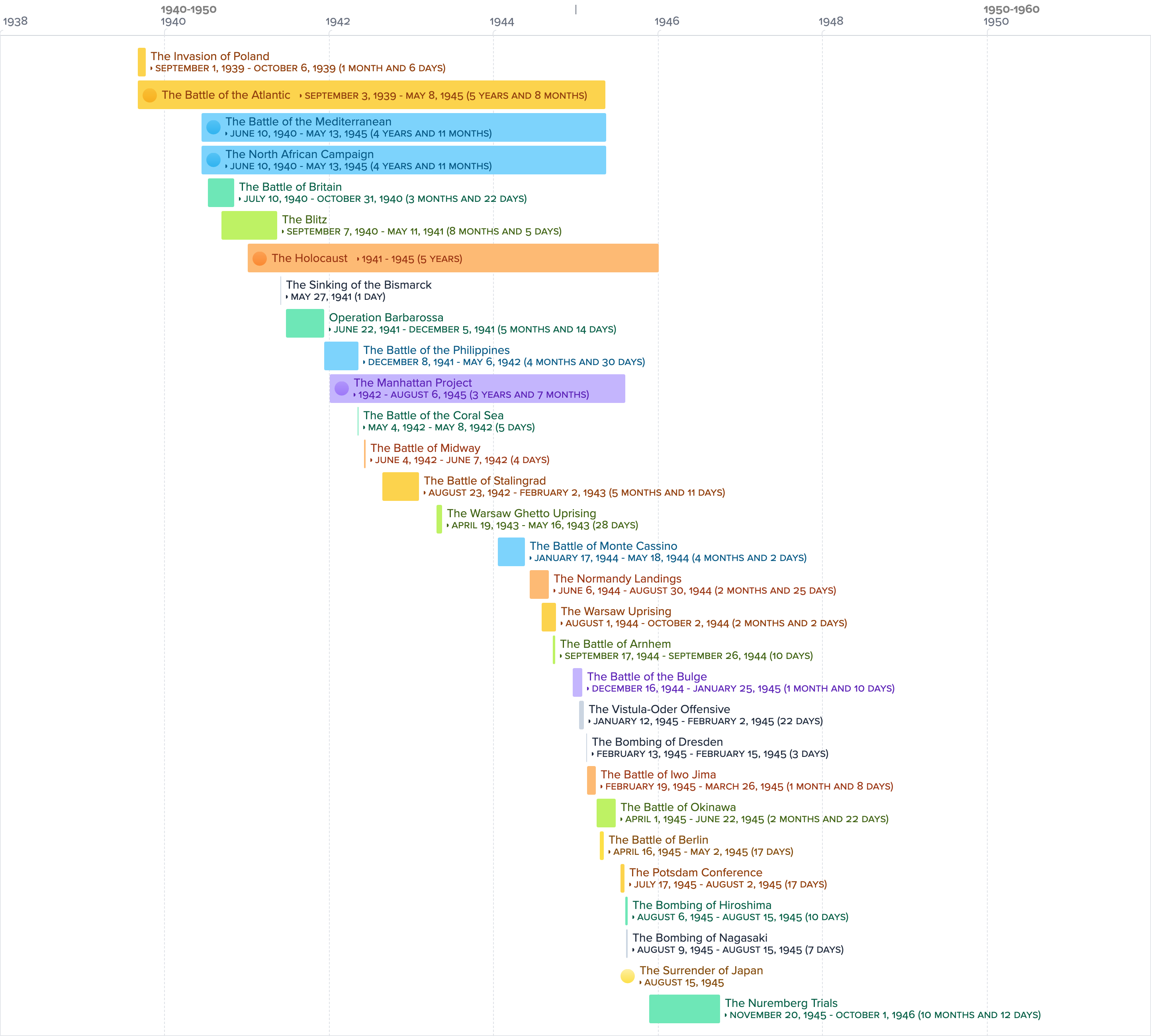
Neat, right?
Preceden’s free plan limits users to 10 events per timeline, so making it easier to populate timelines should lead to more paid conversions and help me grow the business.
And while trickier to do, eventually I’d love for this to support project planning too. Imagine being able to say you want to plan a marketing campaign for your SaaS and it automatically generates tasks and suggests dates.
The v1 will be an in-app tool that people can use, but after I work out the kinks I’ll likely make it a standalone tool that logged out users can use, with an option to sign up to continue working on whatever timeline the tool generates for them.
Codename for this whole project: TimelineGPT :).
LearnGPT
Shortly after ChatGPT launched in late November, I launched LearnGPT.com, a site for browsing, sharing, and discussing ChatGPT prompts:

On launch day I posted it on HackerNews where it received over 350 upvotes and earlier this month it made it to the top 10 again thanks to an interesting prompt about a leaf falling that someone posted.
My initial vision for the site was to start with prompts, then expand it into GPT news, tutorials, apps, and more, and eventually offer paid courses to monetize the site.
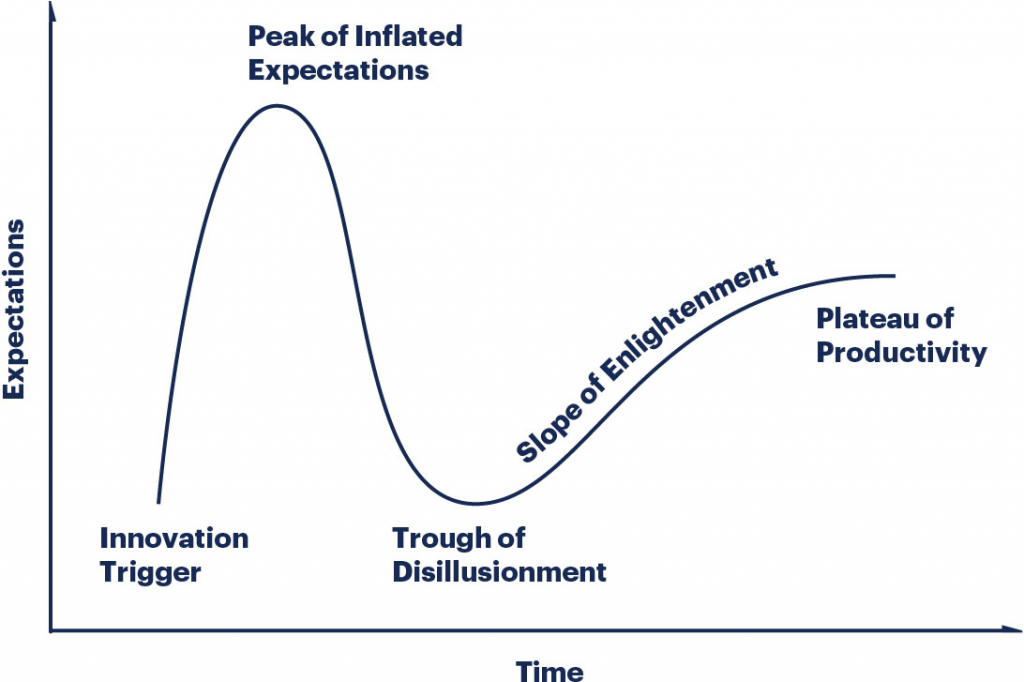
There’s this famous graph showing the typical path that a successful startup takes over its lifetime. I’ve added an arrow showing where LearnGPT is in this journey:
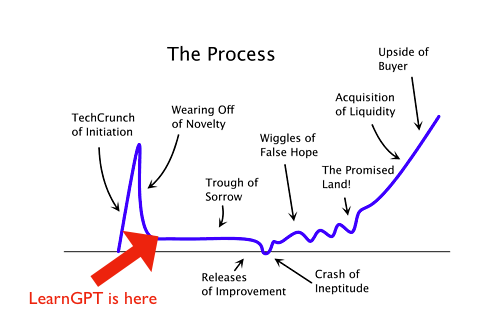
I honestly believe that with a lot of work, I could push LearnGPT past this “trough of sorrow” and build it into a big business along the lines of PyImageSearch or WPBeginner.
But, continuing with it would consume a lot of time and headspace that I could be putting into Preceden.
And unlike other products I’ve started, LearnGPT would require building a community and creating a lot of unique content which doesn’t terribly excite me. I enjoy building products, and writing a lot of content or managing people to write that content is not something I want to spend my days working on.
I considered trying to sell LearnGPT to someone better suited to take it to the next level, but because it’s pre-revenue (and actually burning money thanks to the contractors I’ve had helping with it), it’s not likely to fetch much, and would likely require a fair amount of time to finalize the deal, so I’m just going to throw up a banner about the closure, turn off new sign ups, and shut down the site in a week or two.
And with that, I’ll finally, truly be full time on Preceden and not splitting my time with contracting or other projects.
Onward 🚀