At the end of 2022 I stopped contracting at Help Scout to focus full time on Preceden, a SaaS timeline maker tool that I had been running mostly as a side project since 2010. It’s April now so I figured I’d share an update on how things are going. My periodic Friday updates cover a lot of this too, but it seemed like it’d be useful for me and as well as anyone following along to zoom out and share a high level overview of what I’ve been up to.
Emergent Mind
My intent when I stopped contracting was to focus full time on growing Preceden. However, ChatGPT’s launch at the end of November and my subsequent launch of LearnGPT (a ChatGPT examples site) at the beginning of December wound up complicating things, to say the least.
I first announced in January that I was going to shut down LearnGPT to focus on Preceden. Then I got some offers to buy it, so put it up for sale. Then, I decided not to sell it and to shift directions. Instead of it being a ChatGPT examples site called LearnGPT, it would be a social news community focused on AI and be called Emergent Mind. But no, actually not a social news community, but an AI news aggregator/AI education site powered by GPT-4.
LearnGPT at the beginning of the year:
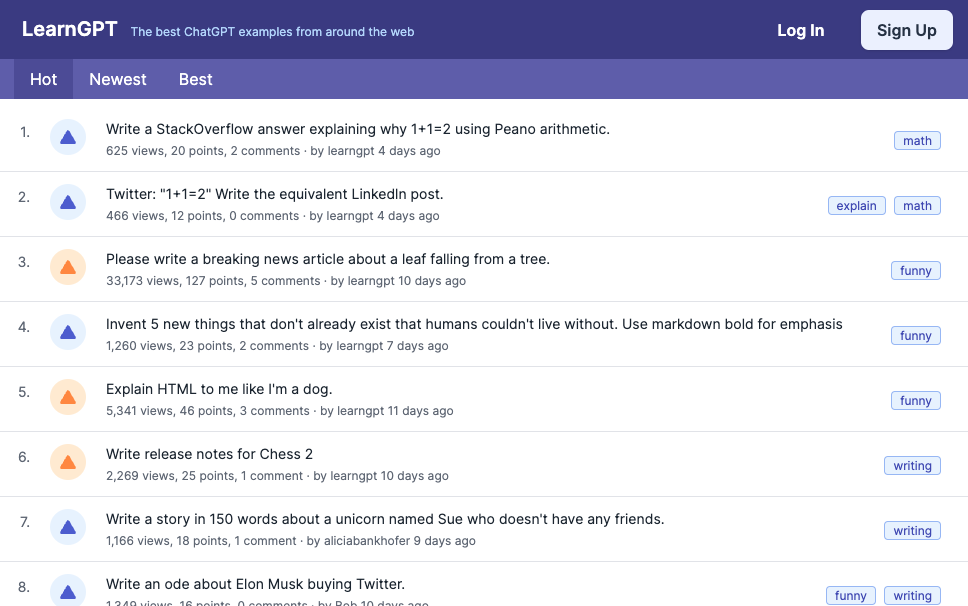
Emergent Mind today:

A chaotic start, for sure, and a savvier entrepreneur likely would have avoided a lot of these missteps. But, for me, it’s how I like to work: ship, learn, and iterate quickly. I wind up heading down a lot of wrong paths with this approach, but usually wind up learning from those mistakes and adjusting course. And for me, this approach usually works better than lots of careful planning, especially for experimental products like Emergent Mind.
And so how is Emergent Mind doing?
It’s doing okay. Traffic is up, sign ups for its upcoming newsletter are up, Discord participation is up, feedback from readers is flowing, and generally it feels like there’s a growing amount of excitement and interest in the site. It hasn’t taken off by any means, but it’s very early still, and I’m optimistic (as always) about its potential. Q2 should see a ton of product improvements, the launch of its GPT4-generated AI newsletter, and hopefully an up-and-to-the-right trend for its traffic.
Preceden
Poor Preceden, never quite getting my full attention, even after supposedly going full time on it.
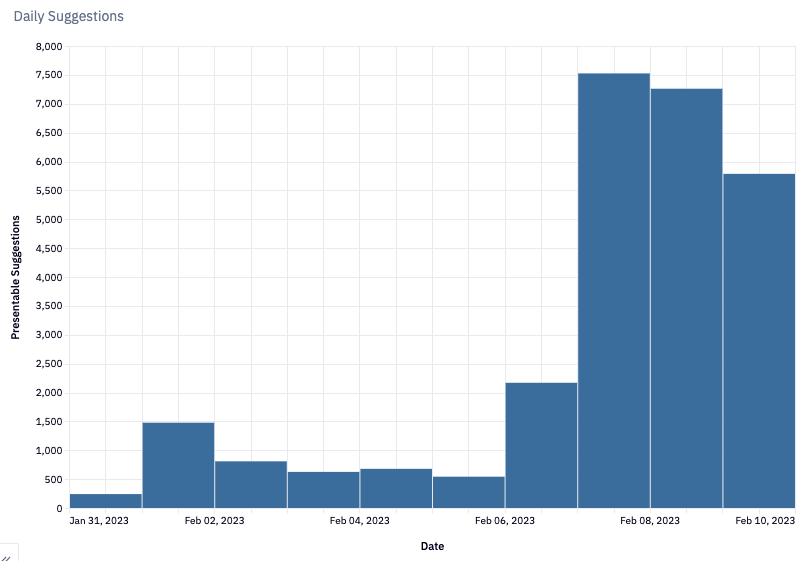
In January I launched an AI Suggestions feature to help users automatically add content to their timelines instead of having to manually build it entirely from scratch. Milan (the part-time designer I work with for both Preceden and Emergent Mind) and I iterated on it a ton in January and February and I’m quite happy with where it wound up.
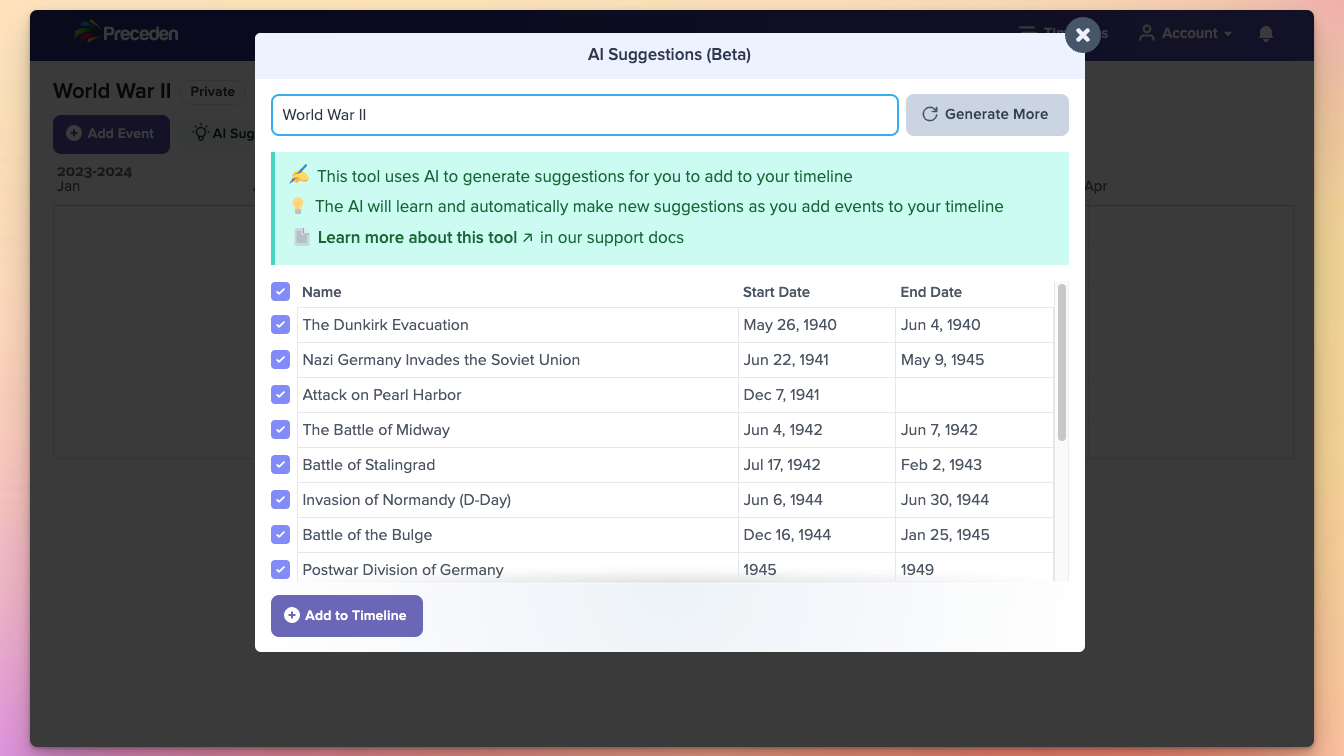
The next big piece – and what we’re working on now – is building a stand-alone version that logged out users can use to generate timelines (and optionally sign up and pay to edit). It’s quite good IMHO and I’m excited to launch it in a few weeks. Which brings me to challenges.
Challenges
Needless to say, juggling two products with just two people can be challenging. Every hour we spend working on Emergent Mind is a hour that we don’t spend working on Preceden.
And remember too that Preceden actually makes money, whereas Emergent Mind for the moment is just burning money. It’s still not obvious to me that deciding to continue working on LearnGPT/Emergent Mind was the right decision. That said, I love having a new, speculative side project, especially one that’s at the cutting edge of what’s possible (an AI-first product powered by GPT-4), has a ton of potential, and one that doesn’t require sifting through a decade of messy, legacy code to update.
As I’ve mentioned in other recent updates too, I haven’t quite figured out how to balance all of these things well. My natural inclination is to jump into VS Code each day and code for 8+ hours straight, jumping between Preceden and Emergent Mind throughout the day. I ship a lot this way, but it takes it toll over time, and I need to do a better job of pacing myself to avoid burnout long term.
What’s next
Q1 definitely felt like I was finding my footing: what products would I be working on going forward and what direction did I want to take those things. Thankfully, I’m mostly on the other side of that. If Emergent Mind does wind up taking off, I’ll have a whole new set of tough decisions to make, but I’ll be lucky if it plays out like that. We will see.
If you find yourself saying to yourself “Matt you really should ______” while reading any of this, I’d love that feedback: @mhmazur on Twitter or matthew.h.mazur@gmail.com.
Thanks for following along 👋.