This morning I was catching up with my friend and coworker Dave Martin and we got to talking about blogging and how we both miss casual blogging: things like writing about what we’ve working on, what issues we’re running into, what we’re learning etc.
The problem for me boils down to this really high bar I have set in my head for what’s worthy of a blog post. I like writing long technical posts and it’s difficult getting used to the idea that short nontechnical posts are just fine too.
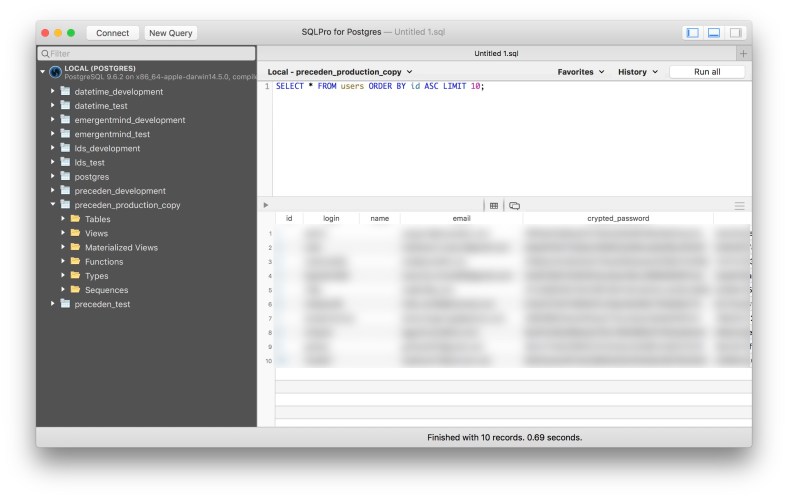
So, in an effort to get back into blogging, here’s a quick update on what I’ve been up to:
I’ve been at Help Scout now for about 4½ months and am really enjoying it. My coworkers are awesome, I love the product, and I’m really getting to level up my data science and analytics skills which I plan to write more about in the future.
My only side project these days is my 7-year old timeline maker service, Preceden. Besides about an hour of customer support each week (via Help Scout, of course), it’s almost entirely passive, though I try to put a few hours into product development and marketing each month to keep improving it.
On the home front, my two year old son and one year old daughter are doing great. I feel incredibly lucky to work remotely which lets me spend more time with them and my wife each day.
I’ve been trying to focus more on my health lately, not because of any major issues, just in an effort to feel more energetic and less stressed each day. Things like sleeping and exercising more, avoiding coffee, meditating, not checking the news so often, etc. I’ve had mixed success maintaining these efforts long term though… it’s a work in progress :).
If we haven’t chatted in a while, I’d love to catch up. Drop me a note anytime by email at matthew.h.mazur@gmail.com or on Twitter/Telegram @mhmazur. Cheers!