
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
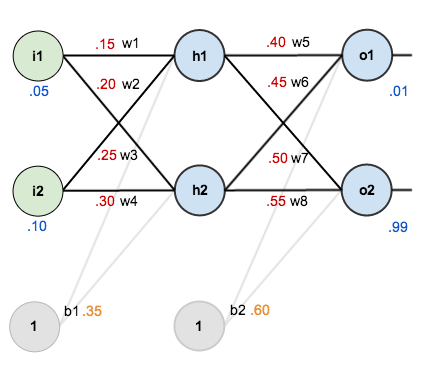
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

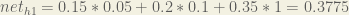
We then squash it using the logistic function to get the output of
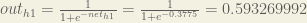
Carrying out the same process for 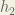
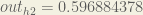
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
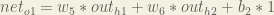
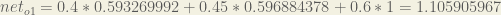

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
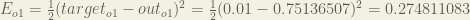
Repeating this process for 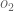
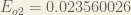
The total error for the neural network is the sum of these errors:
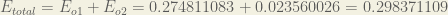
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
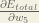
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 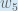 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
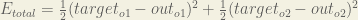
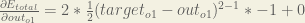
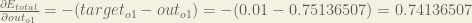
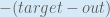
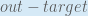
When we take the partial derivative of the total error with respect to 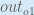

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
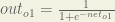

Finally, how much does the total net input of 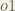
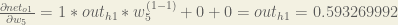
Putting it all together:
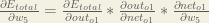
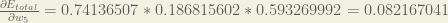
You’ll often see this calculation combined in the form of the delta rule:
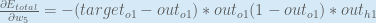
Alternatively, we have 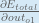
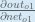

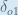


Therefore:
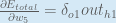
Some sources extract the negative sign from 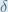
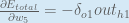
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

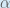 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 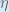 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 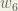

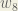
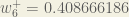
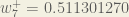
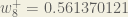
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
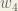
Big picture, here’s what we need to figure out:

Visually:
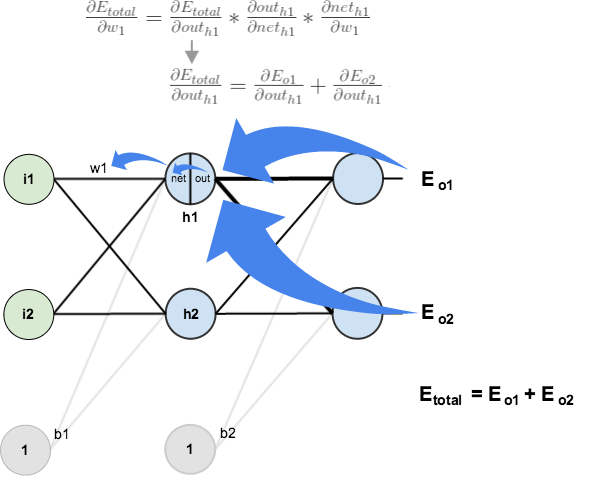
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 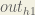
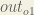
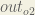
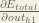
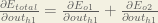
Starting with 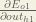
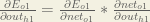
We can calculate 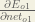
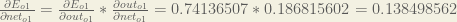
And 

Plugging them in:
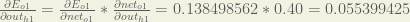
Following the same process for 
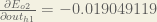
Therefore:
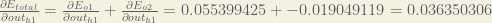
Now that we have 



We calculate the partial derivative of the total net input to

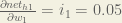
Putting it all together:

You might also see this written as:

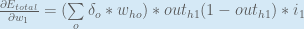
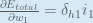
We can now update
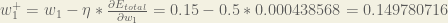
Repeating this for

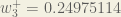
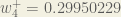
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Having the numbers and the calculations here has really helped me in debugging my implementation of this, so a big thanks for that!
I notice you’ve missed out the calculations for the updates of the bias; I realise that it’s fairly trivial to work out dneto1/db and dneth1/db and chain rule them to find out dEtotal/db, but is this intentional?
Hey Hugo, it’s simple because the materials I read did not include updating the bias :).
Does updating the bias have a big impact on the training efficiency?
Man, you’re awesome! Thank you so much for the post! I wish I’d found it 10 days ago.
There’s one thing I don’t understand — when you’re updating the weight, why’re you *substracting* the derivative? I’ve read another paper, and there the author does *addition* instead. On what does it depends?
Elegantly explained. Thanks for writing.
Just to let you know — here seems to be a bug. It is that the comments here are invisible unless one leave a comment themselves. And after that, a day later, comments again disappears. I don’t see a button like «Show comments», so it is definitely a bug.
thanks for the simple explanation
Why are network outputs set to 0.01 and 0.99? Why are they not set to 0 and 1? In most texts I see them as 0 and 1.
Did you skip the bias update calculations?
never mind! Just saw the other comments!
Thanks for the detailed tutorial. It has been really useful in implementing this algorithm in C#! One discrepancy, when I run this example through my code, I get a different value for one of the hidden layer differentials:
\frac{\partial E_{o2}}{\partial out_{h1}} = -0.019049119
I make this -0.017144205
Which of us is correct?
Nevermind! I found my mistake.
Thanks again for the informative article.
That was heaven, thanks a million.
That was awesome. Thank a ton.
Hi Matt, Can you also please provide a similar example for a convolutional neural network which uses at least 1 convolutional layer and 1 pooling layer ? Surprisingly, I haven’t been able to find ANY similar example for backpropagation, on the internet, for Conv. Neural Network.
TIA.
I haven’t learnt that yet. If you find a good tutorial please let me know.
All hail to “The” Mazur
Thank you so much for your most comprehensive tutorial ever on the internet.
why is bias not updated ?
Hey, in the tutorials I went through they didn’t update the bias which is why I didn’t include it here.
Typically, bias error is equal to the sum of the errors of the neurons that the bias connects to. For example, in regards to your example, b1_error = h1_error + h2_error. Updating the bias’ weight would be adding the product of the summed errors and the learning rate to the bias, ex. b1_weight = b1_error * learning_rate. Although many problems can be learned by a neural network without adjusting biases and there may be better ways to adust bias weights. Also, updating bias weights may cause problems with learning as opposed to keeping them static. As usual with neural networks, through experimentation you may discover more optimal designs.
nice explanations, thanks.
This is perfect. I am able to visualize back propagation algo better after reading this article. Thanks once again!
Brilliant. Thank-you!
If we have more than one sample in our dataset how we can train it by considering all samples, not just one sample?
Invaluable resource you’ve produced. Thank you for this clear, comprehensive, visual explanation. The inner mechanics of backpropagation are no longer a mystery to me.
precisely, intuitively, very easy to understand, great work, thank you.
Thank you very much ,it’s help me well, u really give detail direction to allow me imagine how it works. I really appreciate it. May God repay your kindness thousand time than u do.
Thank You. I have a better insight now
Shouldn’t the derivative of out_o1 wrt net_o1 be net_o1*(1-net_o1)?
No the one stated above is correct, see here for the steps on the gradient of the activation function with respect to its input value (net): https://theclevermachine.wordpress.com/2014/09/08/derivation-derivatives-for-common-neural-network-activation-functions/
Oh and thanks for this Matt – was able to work through your breakdown of the partial derivatives for the Andrew Ng ML Course on coursera :D
shoudn’t the derivative of out_o1 wrt net_o1 be net_o1(1-net_o1)?
thanks so much, I haven’t see tutorial before like this.
Hello. I don’t understand, below the phrase “First, how much does the total error change with respect to the output?”, why there is a (*-1) in the second equation, that eventually changes the result to -(target – output) instead of just (target – output). Can you help me understand?
Thank you!
I’d love to see an answer to this as well: where does that -1 come from? I can make it come from the derivation using the power rule. Help!
Same here, not quite understand where the -1 come from.
This helped me a lot. Thank you so much!
This was awesome. Thanks so much!
Thanks a lot Matt… Appreciated the effort, Kudos
If the error is “squared” but simply E = sum (target – output) , you can still do the calculus to work out the error gradient .. and then update the weights. Where did I go wrong with this logic?
Good afternoon, dear Matt Mazur!
Thank you very much for writing so complete and comprehensive tutorial, everything is understandable and written in accessible way! If is it posdible may I ask following question if I need to compute Jacobian Matrix elements in formula for computing Error Gradient with respect to weight dEtotal/dwi I should just percieve Etotal not as the full error from all outputs but as an error from some certain single output, could you please say is this correct? Could you please say are you not planning to make a simillar tutorial but for computing second order derivatives (backpropagation with partial derivatives of second order)? I have searching internet for tutorial of calculating second order derivatives in backpropagation but did not found anything. Maybe you know some good tutorials for it? I have know that second order partial derivatives (elements of Hessian Matrix) can be approximated by multiplaying Jacobians but wanted to find it’s exact non approximated calculation. Thank you in advance for your reply!
Sincerely
Hi Really it is a great tutorial
hello Matt, Can you please tell me that after updating all weights in first iteration I should update the values of all ‘h’ at-last in first iteration or not.
Why is the error assumed to be sum squared? The errors are not Gaussian. In fact you don’t even sum over the output nodes when updating weights – you do it per node, so there is no need to ensure the sum is >0. Here’s my challenge… http://makeyourownneuralnetwork.blogspot.co.uk/2016/01/why-squared-error-cost-function.html
Thank you for such a comprehensive explanation of backpropagation. I have been trying to understand backpropagation for months but today I finally understood it after reading your this post.
i am writing a gentle intro to neural networks – aimed at being accessible to someone at school approx age 15… here is a draft which includes a very very gentle intro to backprop
https://goo.gl/7uxHlm
i’d appreciate feedback to @myoneuralnet
Thank you so much.
Firstly, thank you VERY much for a great walkthrough of all the steps involved with real values. I managed to create a quick implementation of the methods used, and was able to train successfully.
I was looking to use this setup (but with 4 inputs / 3 outputs) for the famous iris data (http://archive.ics.uci.edu/ml/datasets/Iris). The 3 outputs would be 0.0-1.0 for each classification, as there would be an output weight towards each type.
Unfortunately it doesn’t seem to be able to resolve to an always low error value, and fluctuates drastically as it trains. Is this an indication that a second layer is needed for this type of data?
The first explanation I read that actually makes sense to me. Most just seem to start shovelling maths in your face in the name of “not making it simpler that they should”. Now let’s hope my AI will finally be able to play a game of draughts.
It helps me a lot. thanks for the work!!!
Thanks great tutorial. By any chance would you know how to train for 2 hidden layers?
Great tutorial. By any chance do you know how do backpropagate 2 hidden layers?
I do not, sorry.
Thank you so much! The explanation was so intuitive.
Thank you! The way you explain this is very intuitive.
I’d love your feedback on my attempt to explain the maths and ideas underlying neuralnetworks and backrpop.
Here’s an early draft online. The aim for me is to reach as many people as possible inck teenagers with school maths.
http://makeyourownneuralnetwork.blogspot.co.uk/2016/02/early-draft-feedback-wanted.html
I have a presentation tomorrow on neural networks in a grad class that I’m drowning in. This book is going to save my life