
Back in the day when I worked on Lean Domain Search I got a lot of experience working with Verisign’s .com zone file because that’s what Lean Domain Search uses behind the scenes to check whether a given domain is available to register or not.
I still get a lot of emails asking for details about how it worked so over a series of posts, I’m going to walk through how to work with the zone file and eventually explain exactly how Lean Domain Search works.
What’s a zone file?
A zone file lists all registered domains for a given Top Level Domain (like .com, .net, etc) and the name servers associated with the domain. For example, because this blog is hosted on WordPress.com, the zone file lists the WordPress.com name servers for it:
MATTMAZUR NS NS1.WORDPRESS MATTMAZUR NS NS2.WORDPRESS MATTMAZUR NS NS3.WORDPRESS
How do I get access to the zone file?
Anyone can fill out a form, apply, and get access. There are details on this page. I detailed in this old post on Lean Domain Search how I filled out the form, though it has changed since then so you’ll need to make some adjustments.
What happens after I apply for access?
Verisign will provide you details to log into the FTP to download the zone file:
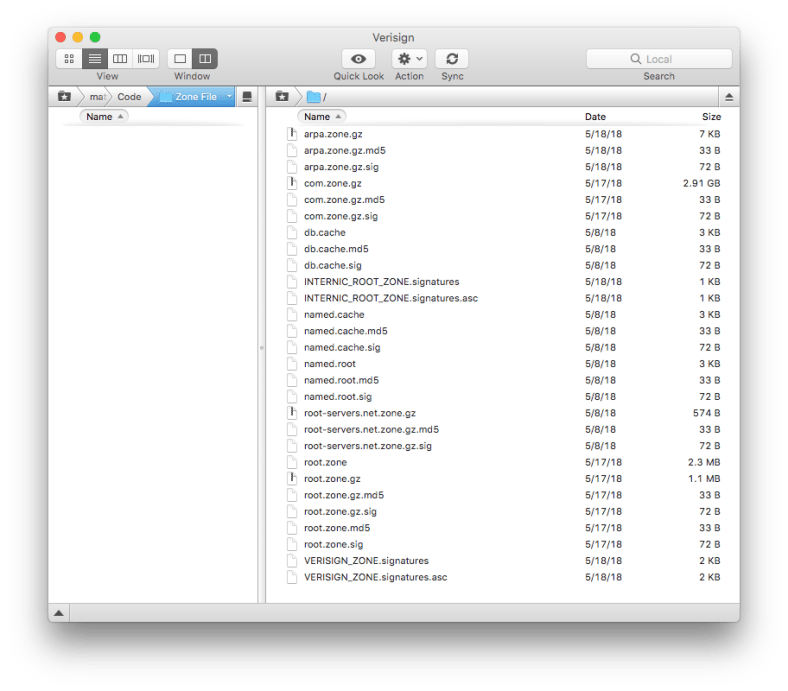
The zone file is that 2.91 GB com.zone.gz which unzipped is 11.47 GB currently.
What’s in the zone file?
It begins with some administrative details, then begins listing domains and their associated name server. Note that registered domains without a name server (such as ones that are close to expiring) are not included in this list.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ; The use of the Data contained in Verisign Inc.'s aggregated | |
| ; .com, and .net top-level domain zone files (including the checksum | |
| ; files) is subject to the restrictions described in the access Agreement | |
| ; with Verisign Inc. | |
| $ORIGIN COM. | |
| $TTL 900 | |
| @ IN SOA a.gtld-servers.net. nstld.verisign-grs.com. ( | |
| 1526140941 ;serial | |
| 1800 ;refresh every 30 min | |
| 900 ;retry every 15 min | |
| 604800 ;expire after a week | |
| 86400 ;minimum of a day | |
| ) | |
| $TTL 172800 | |
| NS A.GTLD-SERVERS.NET. | |
| NS G.GTLD-SERVERS.NET. | |
| NS H.GTLD-SERVERS.NET. | |
| NS C.GTLD-SERVERS.NET. | |
| NS I.GTLD-SERVERS.NET. | |
| NS B.GTLD-SERVERS.NET. | |
| NS D.GTLD-SERVERS.NET. | |
| NS L.GTLD-SERVERS.NET. | |
| NS F.GTLD-SERVERS.NET. | |
| NS J.GTLD-SERVERS.NET. | |
| NS K.GTLD-SERVERS.NET. | |
| NS E.GTLD-SERVERS.NET. | |
| NS M.GTLD-SERVERS.NET. | |
| COM. 86400 DNSKEY 257 3 8 AQPDzldNmMvZFX4NcNJ0uEnKDg7tmv/F3MyQR0lpBmVcNcsIszxNFxsBfKNW9JYCYqpik8366LE7VbIcNRzfp2h9OO8HRl+H+E08zauK8k7evWEmu/6od+2boggPoiEfGNyvNPaSI7FOIroDsnw/taggzHRX1Z7SOiOiPWPNIwSUyWOZ79VmcQ1GLkC6NlYvG3HwYmynQv6oFwGv/KELSw7ZSdrbTQ0HXvZbqMUI7BaMskmvgm1G7oKZ1YiF7O9ioVNc0+7ASbqmZN7Z98EGU/Qh2K/BgUe8Hs0XVcdPKrtyYnoQHd2ynKPcMMlTEih2/2HDHjRPJ2aywIpKNnv4oPo/ | |
| COM. 86400 DNSKEY 256 3 8 AQOz+iBqxZtCKBBqKsO/i9JVchZ2Z1pFCWnj+pFHJi3uPWiYWsAMvtMpInRPfV1Ot9m+8nHPxSkvOL2+bttj4jEK6uUfTarET4wAMSh2k9rX2h+9kVQDjcuRwfFXV5bAmFd3j57hic7FEYVSxXtNUVU7BPaFRHuFr3OrQHQXaR4IeQ== | |
| COM. 86400 NSEC3PARAM 1 0 0 – | |
| COM. 900 RRSIG SOA 8 1 900 20180519160221 20180512145221 36707 COM. Jh63KZtaFJwB86dM+r65iDaGDNWbLsMi7tP/Kf9dYHdILkGpPfO4HOVkKKvMKQpGcrIyl7LPwwfA2VfvISFsWszcqD7SNfP82rHCf8Y1U6JXRS4v23x+0zeaq4LLAaHsejursS8b5W/PsufbXoWgs6oTuCdNEhzit5ql2s2JtUY= | |
| COM. 86400 RRSIG NSEC3PARAM 8 1 86400 20180516044717 20180509033717 36707 COM. eHouT12OKthPi++n+0hgvafEopsN3Q6iCBNVpyvckt3+29ReGd3XugZrx9qASl0Z+sYd8icxHHG2JIMs/ZqrknQIngP24hkmQrRYBAEkNggUzbjxp1CRqdnyeaJ8c8X8WjiFzLk2y7ic4fpxvHcB2MCAIkIRDWlDYjznNaIbsNI= | |
| COM. RRSIG NS 8 1 172800 20180516044717 20180509033717 36707 COM. nmXBe6F4losM2dmCryGopjjJLlhQmYscNgHqvIQ3zbHm59UHe87T6FmHTdtdujmh3D8rW6g2vx2rzWPxLQigd7xh1KyIfCGZODaUB4TPAxadtGCfvu1h00dieCIf/+UIumg5iJBPjlQdCdpAweh1Zw9KUvbWlkRrXLz03jmJ/xg= | |
| COM. 86400 RRSIG DNSKEY 8 1 86400 20180522182533 20180507182033 30909 COM. F7/1eje9GeHOQcuokqfTHeLYxVznTnkF10YAlMTKi7aJiCySWMVwC/0I/om/EvE+Z4AMG+3B/gFy94PpGnOjpaZcimW1syTKJOPPsGXdQD6F1bxnKCD1r+r9HrSIKTe+lzXI7kzakHNZx3zsdYO4aFifr/hiR/YV/wirJjiXxgOFCtUquSlIOeZ7rv8wTf34onLrf2mYk447ByqUWrXJvqJ16pW+ISUFzyroHqgXFluzrMUqlWVJl8mtnQ5ChCk98zZTGCQJc60HDeYWSY3Mbpji2VZS2uQVDTzO3AeEv5GIoLF8jC+UCAeYDiQhZ5HaEn5HSLh/jYe3TOuIm0tOiw== | |
| KITCHENEROKTOBERFEST NS NS1.UNIREGISTRYMARKET.LINK. | |
| KITCHENEROKTOBERFEST NS NS2.UNIREGISTRYMARKET.LINK. | |
| KITCHENFLOORTILE NS NS1.UNIREGISTRYMARKET.LINK. | |
| KITCHENFLOORTILE NS NS2.UNIREGISTRYMARKET.LINK. | |
| KITCHENTABLESET NS NS1.UNIREGISTRYMARKET.LINK. | |
| KITCHENTABLESET NS NS2.UNIREGISTRYMARKET.LINK. |
How can I extract a list of just the domains?
Glad you asked! It takes a little bit of command line fu.
If you’d like to follow along, here are the first 1,000 lines of the zone file. You can download this and use the terminal commands below just like you would if you were working with the entire 317,338,073 line zone file.
1) First, we’ll grab a list of just the domains:
$ awk '{print $1}' com.zone > domains-only.txt
For a line like this:
KITCHENEROKTOBERFEST NS NS1.UNIREGISTRYMARKET.LINK.
This command will return just KITCHENEROKTOBERFEST.
This will also return some non-domains from the administrative section at the top of the zone file, but we’ll filter those out later.
Here’s what domains-only.txt should look like.
2) Next, we’ll sort the results and remove duplicates:
$ sort -u domains-only.txt --output domains-unique.txt
This is necessary because most domains will have multiple name servers, but we don’t want the domain to appear multiple times in our final list of domains.
Here’s what domains-unique.txt should look like.
3) Last but not least, we’ll ensure the results include only domains:
$ LC_ALL=C grep '^[A-Z0-9\-]*$' domains-unique.txt > domains.txt
There are a few things to note here.
First, make sure to use gnu grep, which is not the default on Macs. GNU grep is fast.
The LC_ALL=C forces grep to use the locale C, which tells grep this is an ASCII file, not a UTF-8 file. More details here. While not important for this 1,000-line file, it significantly reduces how much time grep takes on the full 300M+ line zone file.
The ^[A-Z0-9\-]*$ regular expression here looks for lines that are made up of letters, numbers, and dashes. The reason we use a * (0 or more characters) vs + (1 or more characters) is simply because the grep command doesn’t support +.
Technically this regex will match strings that are longer than domains can actually be (the max is 63 characters) as well as strings that start or end with a dash (which isn’t valid for a domain) but there aren’t any of those in the zone file so it’s not a big deal and grep will run faster this way. If you really wanted to get fancy, you could match proper domains, but it will take longer to run: ^[A-Z0-9]([A-Z0-9\-]{0,61}[A-Z0-9])?$
Here’s what domains.txt should look like.
Note that this does include some domain-like strings from the administrative section like 1526140941 which isn’t actually a domain. Depending on what you’re using the zone file for you could remove these lines, but it’s never been a big deal for my use case. Because Lean Domain Search is limited to letters-only domains, it actually just uses ^[A-Z]* for the regex.
Here’s some actual code from Lean Domain Search with these steps above:
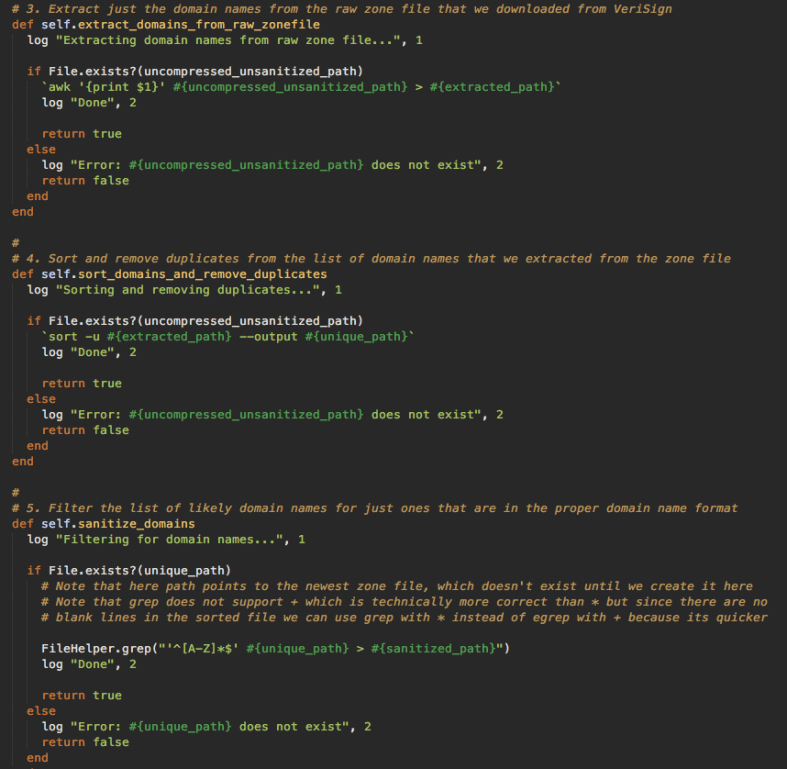
If you run into any trouble or have suggestions on how to improve any of these commands, don’t hesitate to reach out. Cheers!

How much time does this algorithm take to run?
Hey – it’s not that fast – it can take a few hours due to the size of the zone file.
It will also depend on how beefy the machine you run it on is.