
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
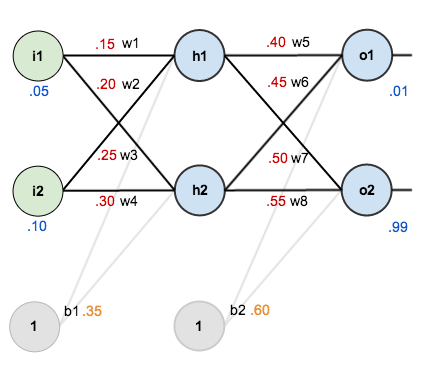
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

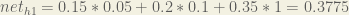
We then squash it using the logistic function to get the output of
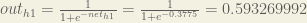
Carrying out the same process for 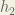
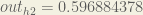
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
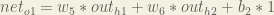
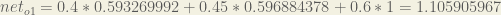

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
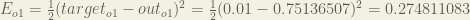
Repeating this process for 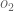
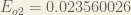
The total error for the neural network is the sum of these errors:
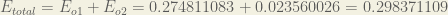
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
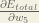
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 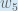 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
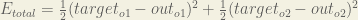
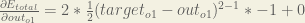
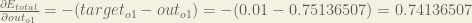
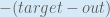
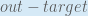
When we take the partial derivative of the total error with respect to 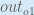

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
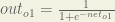

Finally, how much does the total net input of 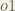
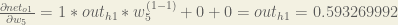
Putting it all together:
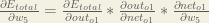
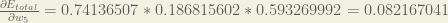
You’ll often see this calculation combined in the form of the delta rule:
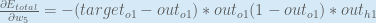
Alternatively, we have 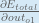
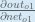

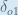


Therefore:
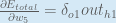
Some sources extract the negative sign from 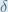
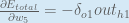
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

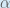 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 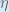 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 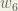

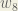
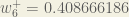
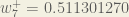
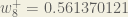
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
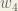
Big picture, here’s what we need to figure out:

Visually:
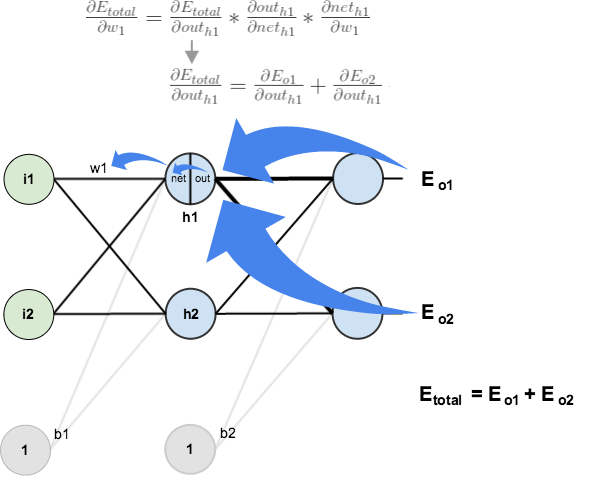
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 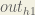
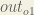
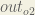
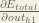
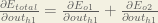
Starting with 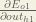
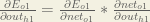
We can calculate 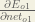
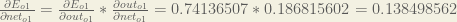
And 

Plugging them in:
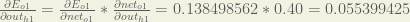
Following the same process for 
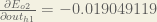
Therefore:
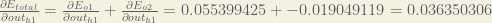
Now that we have 



We calculate the partial derivative of the total net input to

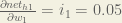
Putting it all together:

You might also see this written as:

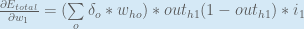
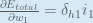
We can now update
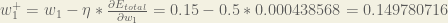
Repeating this for

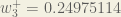
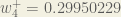
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Thanks for this nice illustration of backpropagation!
I am wondering how the calculations must be modified if we have more than 1 training sample data (e.g. 2 samples).
I reply to myself… I forgot to apply the chainrule
It seems that you have totally forgotten to update b1 and b2! They are part of the weights (parameters) of the network. Or am I missing something here?
We never update bias. Refer Andrew Ng’s Machine Learning course on coursera
I think this is not the case
https://stackoverflow.com/questions/3775032/how-to-update-the-bias-in-neural-network-backpropagation
Thanks to your nice illustration, now I’ve understood backpropagation.
This is exactly what i was needed , great job sir, super easy explanation.
Just wondering about the range of the learning rate. Why can’t it be greater than 1?
Hi Matt
Thanks for giving the link, but i have following queries, can you please clarify
1. Why bias weights are not updated anywhere
2.Outputs at hidden and Output layers are not independent of the initial weights chosen at the input layer. So for calculated optimal weights at input layer (w1 to w4) why final Etot is again differentiated w.r.t w1, instead should we not calculate the errors at the hidden layer using the revised weights of w5 to w8 and then use the same method for calculating revised weights w1 to w4 by differentiating this error at hidden layer w.r.t w1.
3.Error at hidden layer can be calculated as follows: We already know the out puts at the hidden layer in forward propagation , these we will take as initial values, then using the revised weights of w5 to w8 we will back calculate the revised outputs at hidden layer, the difference we can take as errors
4. i calculated the errors as mentioned in step 3, i got the outputs at h1 and h2 are -3.8326165 and 4.6039905. Since these are outputs at hidden layer , these are outputs of sigmoid function so values should always be between 0 and 1, but the values here are outside the outputs of sigmoid function range
Please clarify why and where the flaw is
Question number two is a good one. DId you get an answer yet?
Answer for Q.2, 3 and 4: We do not have ground truth (correct answers) available for hidden layer neurons. So, we can not calculate errors as you have mentioned in point no.3. Error can be calculated only if we have correct answers.
There is not any meaning in doing the same. The values we are getting at hidden layer are due to initial weights (which were randomly guessed). So, these are value are also random guesses.
That’s why we consider Etot only to update all the weights.
Part 2.
Suppose you have a function
y = exp(z)
z = x^2
dy/dx = (dy/dz) * (dz/dx) = (exp(x^2))*2x
think of y is is the function you are optimizing and x is input.
now to calculate gradient with respect to input what we do in backpropagation is we first calculate dz/dx which is 2x (after which we update weights for next forward pass).Then we calculate dy/dz and then we use chain rule to get dy/dx.
If you calculate dy/dz by updated weights you will not get correct gradient .
Awesome tutorial!
But are there possibly calculation errors for the undemonstrated weights? I kept getting slightly different updated weight values for the hidden layer…
But let’s take a simpler one for example:
For dEtotal/dw7, the calculation should be very similar to dEtotal/dw5, by just changing the last partial derivative to dnet o1/dw7, which is essentially out h2.So dEtotal/dw7 = 0.74136507*0.186815602*0.596884378 = 0.08266763
new w7 = 0.5-(0.5*0.08266763)= 0.458666185.
But your answer is 0.511301270…
Perhaps I made a mistake in my calculation? Some clarification would be great!
0.5113012702387375 is right …
The number you have there, 0.08266763, is actually dEtotal/dw6. You will see that applying it to the original w6 yields the value he gave: 0.45 – (0.5*0.08266763) = 0.40866186.
Maybe you confused w7 and w6? The diagram makes it easy to confuse them. W7 is the weight between h1 and o2.
To find dEtotal/dw7 you would have to find:
dEtotal/dout_{o_2} * dout_{o_2}/dnet_{o_2} * dnet_{o_2}/dw7.
so dEtotal/dw7 = -0.21707153 * 0.17551005 * 0.59326999 = -0.02260254
new w7 = 0.5 – (0.5 * -0.02260254) = 0.511301270
hope this helped
After many hours of looking for a resource that can efficiently and clearly explain math behind backprop, I finally found it! Fantastic work!
Heaton in his book on neural networks math say
node deltas are based on [sum] “sum is for derivatives, output is for gradient, else your applying the activation function twice?”
but I’m starting to question his book because he also applies derivatives to the sum
“Ii is important to note that in the above equation, we are multiplying by the output of hidden I. not the sum. When dealing directly with a derivative you should supply the sum Otherwise, you would be indirectly applying the activation function twice.”
but I see your example and one more where that’s not the case
https://github.com/thistleknot/Ann-v2/blob/master/myNueralNet.cpp
I see two examples where the derivative is applied to the output
Very well explained…… Really helped alot in my final exams….. Thanks
Dear Matt,
thank you for the nice illustration!
I built the network and get exactly your outputs:
Weights and Bias of Hidden Layer:
Neuron 1: 0.1497807161327628 0.19956143226552567 0.35
Neuron 2: 0.24975114363236958 0.29950228726473915 0.35
Weights and Bias of Output Layer:
Neuron 1: 0.35891647971788465 0.4086661860762334 0.6
Neuron 2: 0.5113012702387375 0.5613701211079891 0.6
output:
0.7513650695523157 0.7729284653214625
Than I made a experiment with the bias. Without changing the bias I got after 1000 epoches the following outputs:
Weights and Bias of Hidden Layer:
Neuron 1: 0.2820419392605305 0.4640838785210599 0.35
Neuron 2: 0.3805890849512254 0.5611781699024483 0.35
Weights and Bias of Output Layer:
Neuron 1: -3.0640975297007556 -3.034730378052809 0.6
Neuron 2: 2.0517051904569836 2.110885730396752 0.6
output:
0.044075530730776365 0.9572825838174545
With backpropagation of the bias the outputs getting better:
Weights and Bias of Hidden Layer:
Neuron 1: 0.20668916041682514 0.3133783208336505 1.4753841161727905
Neuron 2: 0.3058492464890622 0.4116984929781265 1.4753841161727905
Weights and Bias of Output Layer:
Neuron 1: -2.0761119815104956 -2.038231681376019 -0.08713942766189575
Neuron 2: 2.137631425033325 2.194909264537856 -0.08713942766189575
output:
0.03031757858059988 0.9698293077608338
Sincerly
Albrecht Ehlert from Germany
Could you please share the calculation I mean, how do we update the bias b1 and b2 when we do backpropagation.
@Albrecht Ehlert Could you please share the calculation I mean, how do we update the bias b1 and b2 when we do backpropagation.
Hi Hello§,
here is the output of my program:
————————————————–
weights and bias of hidden layer:
neuron 1: 0.15 0.2 0.35
neuron 2: 0.25 0.3 0.35
weights and bias of output layer:
neuron 1: 0.4 0.45 0.6
neuron 2: 0.5 0.55 0.6
output 1: 0.7513650695523157 0.7729284653214625
average of total errors: 0.2983711087600027
learned in percent: 0
epoche: 1 number of data: 1
output:
0.7513650695523157 0.7729284653214625
total error before: 0.2983711087600027
backpropagation output layer
output: 0.7513650695523157 target: 0.01
new weight: 0.35891647971788465
new weight: 0.4086661860762334
bias calculation 1: 0.5307507191857215
output: 0.7729284653214625 target: 0.99
new weight: 0.5113012702387375
new weight: 0.5613701211079891
bias calculation 2: 0.6190491182582781
backpropagation hidden layer
weight adjustment: -1.8236143879704674E-4
new weight: 0.14981763856120295
weight adjustment: -3.647228775940935E-4
new weight: 0.19963527712240592
bias calculation 1: 0.34635277122405905
weight adjustment: -2.1181480223381405E-4
new weight: 0.2497881851977662
weight adjustment: -4.236296044676281E-4
new weight: 0.29957637039553237
bias calculation 2: 0.3457637039553237
————————————————————–
You calculate the bias like a regular weight.
But you get for b2 two results:
bias calculation 1: 0,5307507191857215
bias calculation 2: 0.6190491182582781
The program takes the average of both as the new b2: 0,5748999187219998
The same with b1:
bias calculation 1: 0.34635277122405905
bias calculation 2: 0.3457637039553237
The program takes the average of both as the new b1: 0,3460582375896914
I finally understood BP thanks to you. You are my hero.
When you derive E_total for out_o1 could you please explain where the -1 comes from? I get the normal derivative and the 0 for the second error term but I don’t get where the -1 appeared from.
It’s because of the chain rule. In the original equation (1/2)(target – out_{o1})^2, when you end up taking the derivative of the (…)^2 part, you have to multiply that by the derivative of the inside. The derivative of the inside with respect to out_{o1} is 0 – 1= -1
I read many explanations on back propagation, you are the best in explaining the process. Thank you very much.
Matt, thanks a lot for the explanation….However, I noticed
net_{h1} = 0.15 * 0.05 + 0.2 * 0.1 + 0.35 * 1 = 0.3775
should it be
net_{h1} = 0.15 * 0.05 + 0.25 * 0.1 + 0.35 * 1 = 0.3825
ie. 0.25 instead of 0.2 (based on the network weights) ?
Again I greatly appreciate all the explanation
I think you may have misread the second diagram (to be fair its very confusingly labeled). Take a look at the first diagram in the section “The Backwards Pass.” Here we see that neuron o_1 has associated weights w5 & w6. If you look back at the first diagram, w5 & w6 are the top two labeled weights, so it would follow logically that neuron h1 is has the weights w1 & w2.
W2 has a value of .20, which is consistent with the way he performed the other calculations.
Great explanation Matt! I really appreciate your work. I noticed a small mistake:
I noticed a small mistake at the end of the post:
net_{h1} = w_1 * i_1 + w_3 * i_2 + b_1 * 1
should be:
net_{h1} = w_1 * i_1 + w_2 * i_2 + b_1 * 1
When calculating for w1, why are you doing it like :
Eo1/OUTh1 = Eo1/NETo1 * NETo1/OUTh1
and not like:
Eo1/OUTh1 = Eo1/OUTo1 * OUTo1/NETo1 * NETo1/OUTh1
Why are you going from Eo1 to NetO1 directly, when there is OUTo1 in the middle.
Eo1/OUTh1 = Eo1/OUTo1 * OUTo1/NETo1 * NETo1/OUTh1. Thanks for giving this explanation bro.
Hi طیب مظہر! Did you find the answer to the question?
any reason why back propagation is necessary ? Can we not do this with just forward propagation in a brute force way ? or is the forward propagation is somehow much slower than back propagation.
given that we have a network with weights,
can we not get dE(over all training examples)/dWi as follows:
[1] store current error Ec across all samples as sum of [ Oactual – Odesired } ^2 for all output nodes of all samples
[2] simply change the Wi by say 0.001 and propagate the change through the network and get new error En over all training examples.
[3] then set Wi back to its old value. (so we do not mess it up for another Wi)
[4] and then dE/dWi = (En – Ec) / 0.001
[5] Do this for all weights to get all weight sensitivities.
[6] then change all weights Wi = Wi – dE/DWi * learning rate
[7] propagate through the network get Ec
[8] Repeat 1 to 7 until Ec is lower than acceptable error threshold
Great article! Just what I was looking for, thank you.
Thank you for your very well explained paper.
I think u got the index of w3 in neto1 wrong. It should be 2 or i am wrong ?
I noticed the exponential E^-x where x = 0.3775 ( in sigmoid calculation) from my phone gives me -1.026 which is diff from math/torch.exp which gives 0.6856. Why is this different?
Really great explaination, thank you very much !!! But is there any intuition why the value of derivative E_o1 to out_o1 is equal to the value of derivative E_total to out_o1 = .74136507 ?
I tried building model along these lines.
Innumerable thanks!! the results match exactly as specified.
Matt, thanks a lot for making dummies like me understand this with very simple example.
cheers!
Great article but how about more than one training data? thank you
Hi Matt,
Thanks for your post. I found it super useful!
I followed your steps and built my NN model, fed some data into it.
A weird thing happened.
The loss does converge but the values of the whole prediction dataset are always greater than the target dataset (a significant difference exists between the mean of them ). It seems that the prediction cannot reach the range of the target.
Is there something wrong with my NN design? or the initialization?
Thank you in advance
Love it!
Finally I understood backpropagation and its meaning!
I am going to share this link on a forum of my uni course, if is ok!
Took me some time to figure out that all the calculations have have been done only up to 9 decimal places.
You are a great teacher! <3 I wish You all kinds of good in Your life my friend!
Just to be clear because I’m the second person to make this mistake. If you are getting 0.3825 instead of 0.3775, swap your w2 and w3, and also check your w6 and w7 to see if you made the same mistake there. w2 leads to the first hidden node NOT the second one. (The diagram could also be more clearly labeled.)
What about providing several different input values to the net? My problem is that it does learn to provide the expected values, but it only works with one training example. If I repeatedly give it different examples with corresponding targets, it only memorizes the last one and outputs the last target no matter what values I give to it. I tried changing weights by a value which is an average of weight changing values for each of the examples – did not work, the training process got stuck with outputs holding averages of each target vector (so if we have target vectors (1, 1), (0, 0) and (0, 1), the outputs are (0.33, 0.67)), and it also fails to minimize the cost which is an average of costs for each training example. How do we manage network training with a bunch of different input and target vectors?
I stand corrected, “it only memorizes the last one and outputs the last target no matter what values I give to i” it outputs values in accordance with the weights adjusted to output the last target vector when the net is given the last input vector from the example set
What about providing several different input values to the net? My problem is that it does learn to provide the expected values, but it only works with one training example. If I repeatedly give it different examples with corresponding targets, it only memorizes the last one and outputs values in accordance with the weights adjusted to provide the last target vector when given the last example from the set. I tried changing weights by a value which is an average of weight changing values for each of the examples – did not work, the training process got stuck with outputs holding averages of each target vector (so if we have target vectors (1, 1), (0, 0) and (0, 1), the outputs are (0.33, 0.67)), and it also fails to minimize the cost which is an average of costs for each training example. How do we manage network training with a bunch of different input and target vectors?
why my comments get deleted?
They’re not – I don’t delete any. Not sure what’s up.
Thank you! it so helpful, but I couldn’t find the true value to update weight1. Could you help me?
the claculation of nethi is wrong
0.075+0.020+0.350= 0.445
Nice explanation! I got a question: what if we try to train two neural networks, one is wide and the other is deep, with the same number of neurons and training epochs. Which one would be faster?
It shouldn’t be different in time for train or run but it can be different in performance. You can find articles to give you an idea of how many layers or neurons per layer is better for this or that type of problem. But it isn’t a clear fix answer for that and you can find the best performance with try and error.
very good illustration, thank you a lot, I have found lots of bugs in my code :)
Thanks it’s now more clear for me. Could you please explain why the value of derivative E_o1 to out_o1 is equal to the value of derivative E_total to out_o1 = .74136507 ? (at the beginning of Hidden layer calculations)
HI,
I’ve used your code as a reference for the XOR problem and am running into an issue with local minima.
I sometimes get the desired output with an error rate around .001 and other times I get stuck at an error rate of around .3-.4.
I’ve tried using a fixed set of initial weights and biases which increases the probability of getting the desired results.
However I still end up with some instances of getting stuck in local minima.
I compare it to your code that seems to never get stuck in local minima, and after reviewing your code and my code multiple times I’m unsure as to why this might be happening.
If you could point me in a better direction I would be grateful.