
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
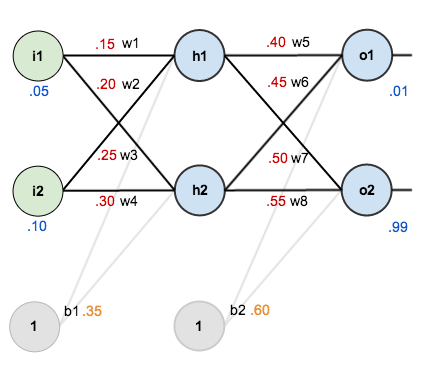
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

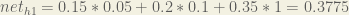
We then squash it using the logistic function to get the output of
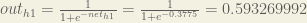
Carrying out the same process for 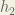
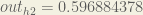
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
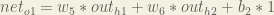
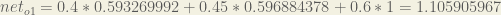

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
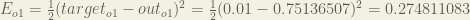
Repeating this process for 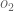
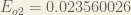
The total error for the neural network is the sum of these errors:
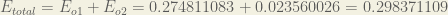
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
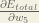
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 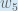 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
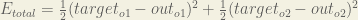
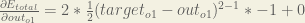
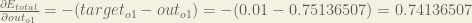
When we take the partial derivative of the total error with respect to 

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:

Finally, how much does the total net input of 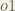
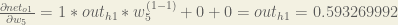
Putting it all together:
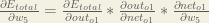
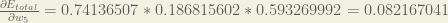
You’ll often see this calculation combined in the form of the delta rule:
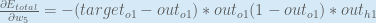
Alternatively, we have 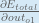
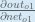

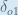


Therefore:
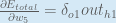
Some sources extract the negative sign from 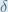
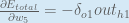
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

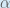 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 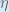 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 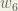

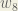
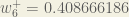
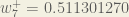
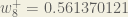
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
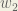
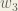
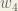
Big picture, here’s what we need to figure out:

Visually:
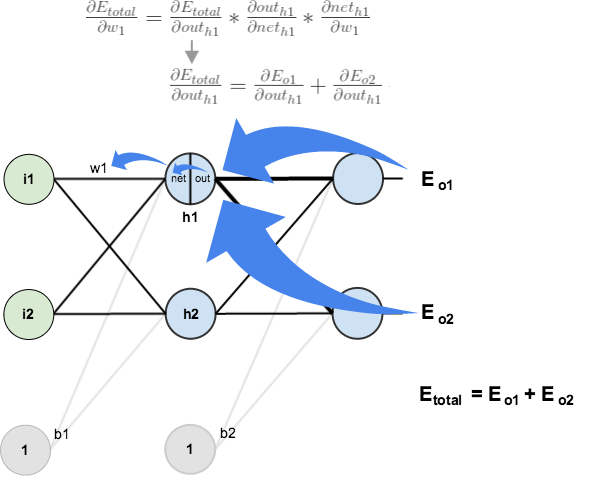
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 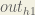
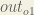
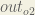
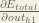
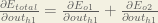
Starting with 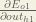
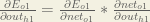
We can calculate 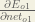
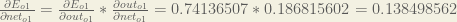
And 

Plugging them in:
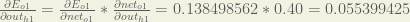
Following the same process for 
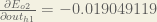
Therefore:
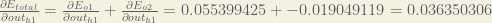
Now that we have 



We calculate the partial derivative of the total net input to

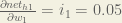
Putting it all together:

You might also see this written as:

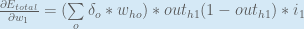
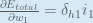
We can now update
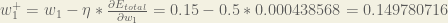
Repeating this for

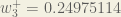
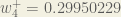
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Yeah, same query. Don’t we need to update the biases?
Excellent explanation
Excellent article. Can you please explain a little bit “pattern detection in EEG signals” where at the output node one would classify “YES” (if certain pattern detected) and “NO” (if certain pattern not detected). Only thing I’m unable to understand is that how an actual pattern can be represented with a single Label & where do we use the actual pattern in NN.
Hello Matt, great tutorial !
A question please,
When you calculate w5 in the backpropagatino pass, you got that Derivative(Etotal) / Derivative(w5) = 0,082167041.
I simulated the NN here and when I changed w5 from 0,4 to 1,4 , the Etotal didn´t changed by 0,082167041. What does it means the Derivative(Etotal) / Derivative(w5) ? How can we interpret this ?
Thanks
Thor
what if we have a deep network, like 1+ hidden layers ? then how this error propogation is done ? ( I would like to know how the equation will get updated ).
Excellent explanation . Thank you so much .
A lot of steps are missing in this tutorial, but I’m pretty sure the numbers w6+ and w7+ are wrong.
Further to my previous comment, pretty sure you got w6+ and w7+ wrong. You have mixed up the two deltas that go into their calculations.
nice work
I believe there is an issue with the partial derivative of the output of a neuron with respect to its weighted input (or `net` as is used here).
Instead of it equaling out_o1 * (1 – out_o1), shouldn’t it be equal to net_o1 * (1 – net_o1) ?
Great explanation! It helped me so much, thank you!
This is great! However I feel that the OUTh1 is incorrect. (0.25*0.1)+(0.3*0.1)+(0.35)=0.405, and 1/(1+e^(-0.405))=0.599888368864, not 0.596884378 as stated above.
But this explanation is great, thank you for helping me learn!
Dear Matt,
Thanks for this lovely post. I have tried to implement this using C#, source uploaded at github https://github.com/animesh/ann.
I could reproduce values after first iteration, however after 10000 iterations, you report
Error 0.000035085
Output1 0.015912196 (vs 0.01 target)
Output2 0.984065734 (vs 0.99 target).
while i am getting
3.51018778297886E-05
0.0159136204435507
0.984064273514624
changes are minor, but I am just wondering if we are actually diverging the values due to the way double type is handled in Python and C#?
Best regards,
Ani
Hi can you please help me understand these…
The point that I canNOT relate or understand clearly is,
a) why should we use derivative in neural network, how exactly does it help
b) Why should we activation function, in most cases its Sigmoid function.
c) I could not get a complete picture of how derivatives helps neural network.
d) What’s actually happening with all those calculations and derivatives
Hi Matt,
thank you so much for this tutorial. I really appreciated the numerical values you provided, they helped me check that my own computations were correct.
Your tutorial inspired me to write a python code that would replicate the neural network from your tutorial. I made the same neural net (with the same initial values as in your tutorial) run for 1000 steps and displayed the evolution of the outputs and errors in a plot.
Here’s how the plot looks like :

The python code is on gitlab here : https://gitlab.com/NaysanSaran/simple-python-neural-net-example
It’s my very first time writing a neural net so I would love to have your input on how I can make the computations more efficient.
So as far as I can understand, the biases are constants so we don’t need to bother changing them but why don’t we just get rid of them?
the best tutorial on the web.
I have a clear intuition now, thanks for you work. I want to translate it into Chinese, if you don’t mind. But, to be honest, what I should do is only to edit some conjunctions, since you have made so many pictures which are easy to understand! :)
It’s fine if you want to translate to Chinese :)
Thanks again!
Great tutorial, thanks a bunch!
Why is it that w1 can be readjusted without including w7? I ask because w5 is included, and both w5 and w7 connect to outputs so I can’t see the difference.
Reblogged this on netZyron.
Thank you very much for your article. It is very well explained. I am reading neuralnetworksanddeeplearning by Michael Nielsen and had trouble understanding backpropagation. Your explanation is very intuitive and extremely useful in understanding how to do it by hand without reading lots of lots of text several times.
This is a really clear explanation about backpropagation, it has been a pleasant reading. Thank you very much for sharing!
Thanks for this article. I think I found one typo, correct me if I’m wrong. In the last blue frame, first formula. Shouldn’t it be d_Eo / d_out_h1 instead of d_Etotal / d_out_ o ?
Thank you for a good example.
I have a question.
Is it possible to implement the algorithm in Matlab?
Thanks for this article…
How can this be generalised? Using this algorithm I’ve tried to create a network with n inputs, m hidden neurons and m p output neurons however each time I train the network to a sample, it forgets about the one it has previously learned. Even if I knew how to train the network you’ve given above to give a different output for two different inputs I’d be grateful.
Also, in order for your any of the outputs to be updated to anything less than 0.5 it would seem that the input, or net input as you call it, would have to be negative, oweing to the fact that the activation function is antisymmetric. This can’t be true, at least as far as I can see, because the adjustments to the weights are ever diminishing and so the weights never go below zero. Perhaps my implementation is bugged though.
Thanks so much
Thanks a lot for the explanation. I have never seen such a crystal clear tutorial of neural nets ever before.
this is wonderful,I wish i have seen this document earlier.
If the neural network has two hidden layers, how would be the expression for the partial derivative dE/dW1?
Thanks dude! finally, i could understand very well this issue.
yes … me too… very incredible tutorial… thx
THANK’S I helped a lot
Greetings from Peru
Great explaination, Thanks!
Great post, clear concepts! Thanks!!
Helps a lot, thanks
nice one
It was a revelation. Equations with many Greek letters does not explain much alone. Keep going!
Btw, why dont you calculate gradients for biases ?
Some guides do that, others don’t. I didn’t for this tutorial.
Is there a possibility you can show us how to calculate the gradients for the biases? Love this tutorial by the way it is very informative and clear!
Can you please do a tutorial for back propagation in Elmann recurrent neural networks!!…. It would be of a lot of help…
Great article! I struggle with one aspect though and that is calculating the partial derivatives from out/net, using (output * (1.0 – output). In cases where output is 0 or 1, it effectively kills the pass through of error. How do you handle this when, especially at startup, the network can devolve (or even start) in this state?
Thanks!
How do you get an output of exactly 0 or 1? The only neuron that can output them is the input neuron (because they output what they take in), but we don’t do anything with them. For any other neuron, output is the result of sigmoid function so it cannot be exactly 0 or 1.
You can round the output to get 0 or 1.
should be the first stop for anyone to understand backward propagation, very well explained…thanks a lot
Very informative, Thank you
Best one i found on internet for backpropagation
In trying to understand NNs better I have produced a Google Docs spreadsheet that almost does what this link talks about:
I was hoping that going through that exercise will give me a better mental picture of what a NN is doing when it is working. I should be able to see easily by direct comparison what happens to the set of numbers with each iteration (ie each new pair of FP and BP sheets). I think I have got it nearly working except for the stuff in the dashed purple box. I want to confirm that the purple arrow is pointing to the wrong blue arrow? I also want someone to tell me how to implement the purple box . . If I could work that out I think I could then repeat the FR and BP sheets and see how the Diff column evolves . . here is the current SS:
https://docs.google.com/spreadsheets/d/1-YxT_PuzDt3VXrOucOBHzxBpSiB5USiy2ULaqE75Wcg/pubhtml
I still found your description above heavy going – could you help me finish my spreadsheet or turn your example into a spreadsheet?
Thanks,
Phil.
I still found your example above a little heavy going – in trying to understand these things better I had produced a Google Docs spreadsheet that almost does what this link talks about:
I was hoping that going through that exercise will give me a better mental picture of what a NN is doing when it is working. I should be able to see easily by direct comparison what happens to the set of numbers with each iteration (ie each new pair of FP and BP sheets). I think I have got it nearly working except for the stuff in the dashed purple box. I want to confirm that the purple arrow is pointing to the wrong blue arrow? I also want someone to tell me how to implement the purple box . . If I could work that out I think I could then repeat the FR and BP sheets and see how the Diff column evolves . . here is the current SS:
https://docs.google.com/spreadsheets/d/1-YxT_PuzDt3VXrOucOBHzxBpSiB5USiy2ULaqE75Wcg/pubhtml
Could you help me finish this or maybe turn your example into a spreadsheet?
Thanks,
Phil.