
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
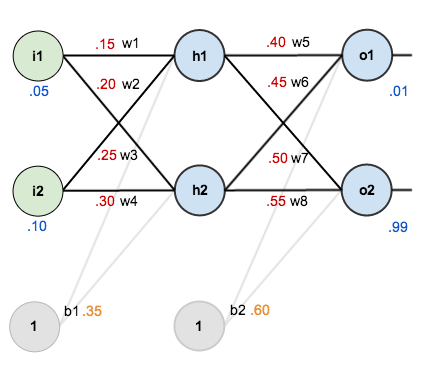
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

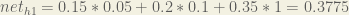
We then squash it using the logistic function to get the output of
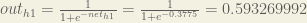
Carrying out the same process for 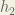
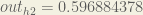
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
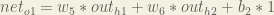
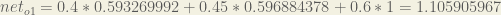

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
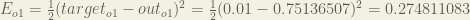
Repeating this process for 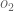
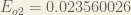
The total error for the neural network is the sum of these errors:
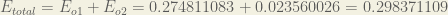
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
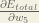
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 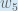 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
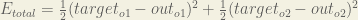
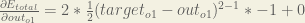
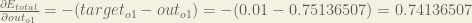
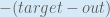
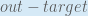
When we take the partial derivative of the total error with respect to 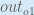

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
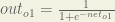

Finally, how much does the total net input of 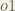
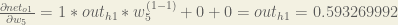
Putting it all together:
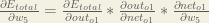
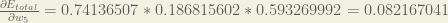
You’ll often see this calculation combined in the form of the delta rule:
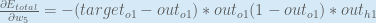
Alternatively, we have 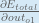
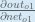

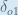


Therefore:
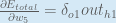
Some sources extract the negative sign from 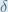
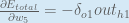
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

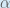 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 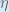 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 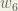

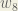
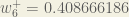
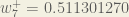
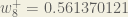
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
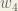
Big picture, here’s what we need to figure out:

Visually:
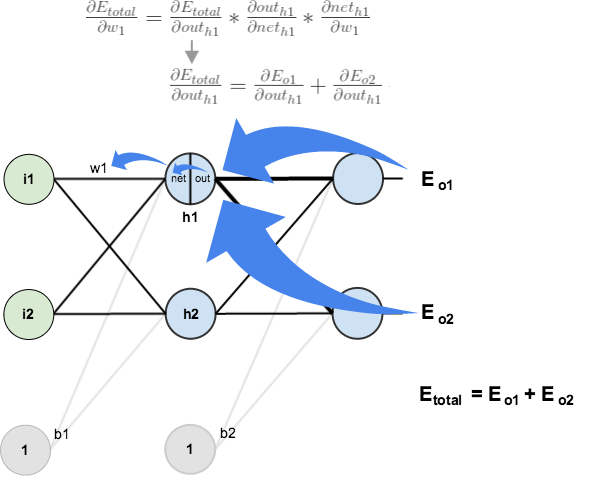
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 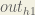
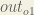
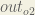
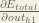
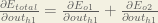
Starting with 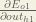
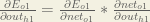
We can calculate 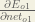
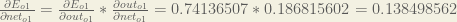
And 

Plugging them in:
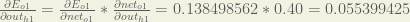
Following the same process for 
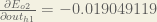
Therefore:
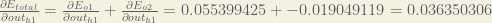
Now that we have 



We calculate the partial derivative of the total net input to

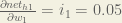
Putting it all together:

You might also see this written as:

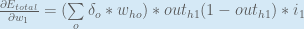
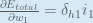
We can now update
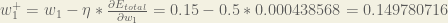
Repeating this for

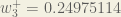
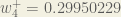
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Awesome!
This was a pleasure to read with beautiful diagrams and numbers to make it real. Thank you.
Best explanation so far, thanks so much!
This is probably the best explanation I’ve seen so far. Thank you so much!
Thank you for your great explanation! but i have some questions about it.
in your post, at [The Backwards Pass // Output Layer] part,
(d E_total/ d out_o1) = 0.74136507.
and at [The Backwards Pass // Hidden Layer] part, you said
‘We can calculate (d E_o1/d out_o1) using values we calculated earlier.’
(d E_o1/d out_o1) = 0.74136507.
(d E_o1/d out_o1) = (d E_total/ d out_o1) ?
is this two partial deviation values are same? please reply me!
I wonder this too, is there anybody?
Yeah, I wonder this too, anybody?
I guess it is because, E_O2 is independent of Out_O1 and is treated as a constant and when you take the derivative it is zero. Could be wrong.
maybe:
E_total = E_o1 + E_o2
d(E_total) = d(E_o1 + E_o2) = d(E_o1) + d(E_o2)
so, with respect to d_out1, the second part will be zero.
As @Shree Ranga Raju said.
I think, Yes
those are same:
E_total = E_output1 + E_output2 => E_total = E_output1 + 0 for E_o1 and E_total = 0 + E_output2 for E_o2.
for calculate E_o1, E_output2 can’t effect and is equal 0 then they have same amount.
Reblogged this on irusin.
A very helpful explanation thank you.
amazing article, those diagrams are very clear. thanks.
i have same question, it was asked before. how do we update biases weights?
Thanks! Best explanation I have ever read.
Question: Does it make any difference if I choose bias to be -1?
Hi, thanks for this explanation. What I don’t understand is why the weight adjustment is dEtot/dw instead of (dw/dEtot)*(Etot)*(eta).
Thanks, Rich
Nice explanation. Very helpful article.
Best explanation I’ve seen so far on backpropagation. Great job, many thanks!
Thanks much…
Why is the weight for the bias the same for a layer? For instance, for the input layer, the bias going into the hidden layer nodes h1, h1 has weight b2.
amazing! Thanks!
How can I implement it for multiple hidden layers (more than one) ?
I think, You can do it for any number of hidden layer just you need to repeat process between output layer and hidden layer(Section Hidden Layer) for extra hidden layer you have.
Nice tutorial thanks. But how can we make this to work for multiple hidden layers(not a single hidden layer) ?
Nice Explanation. Thank you.
Awesome!
Thanks.
Very good article, however:
neth1 = 0.15*0.5 + 0.1*0.2 + 1*0.35 is not equal 0.3775 but 0.445
I suggest you examining all the calculations in order to improve your credibility
Sorry, I was wrong. You have 0.05 not 0.5. I made a mistake by wrong copying data.
I enjoyed your post tremendous and it helps me, to a great extend, understand how a neural net work in enough detail to implement one.
Thank you very much!
You are explaining that dE/dO1 = 1/2 * 2 * (target1 – output1) * (-1) = 0.7414
But dE/dO2 = 1/2 * 2 * (target2 – output2) * (-1) = -0.217
Above you have considered it as +0.217
By taking it as negative, makes w7+ = 0.48871 and not 0.51130 as you have calculated.
Could you verify it?
Sorry my bad
Thank you very much, this was a great explanation and I could check the results of my neural network output by confronting them with your calculations. I also managed to improve the error reduction after 10000 cycles by updating the biases of neurons during backpropagation.
Thank you so much! That was brilliant!
Excellent! Thanks for writing this up.
Thank you. This is easy to follow. This helps me a lot.
As far as I understand, all these calculations are made to get two-dimensional output vector (target) as a result of two-dimensional input vector. I think, one linear system of two equations can give the same result. Am I right?
Nops. That neural network forms a non linear equation. Note that each node act like a function and each of them have a output to another function. This kind of network can produce equations like f(x,y) = x^1.24 + y^0.59 +2.25x + 1.1345x*0.1y – 0.33y, depending of number of nodes.
It was an amazing tutorial. Succint, yet comprehensive. Thanks a million.
Nicely done! Thanks for doing this – helped me a lot!
Very nice explanation with sound examples.
Thank you,
Very clear and easy to understand.
It gave me an end-to-end vision.
Other articles only explain math calculus, but not a systematic diagrama.
Good work
Amazing explanation. Thank you!
Thank you so much!! This made this algorithm so much more clear to me. The one typo I noticed is that the error after 10000 epochs in your github code is 3.5102e-05 and when I created my own network I got the same.(3.510187782978861e-05) but the article says 0.000035085.
Quick question to anyone who can answer… I know that the Bias inputs remain 1 at all times. But do b1 and b2 change throughout the algorithm as w1-w8 do? Or do we keep them as the initial guess values?
Thank you in advance.
It stays the same throughout
Yes, in practice biases get updated as well. Moreover, each of the neurons should have its own bias. For example, this means that in practice there would not be just one b1 for both h1 and h2. Each of those 2 neurons would have a separate bias that also gets updated in the backward pass.
I had the same question and from available online literature that I read up on, it seems that the bias weights should also get adjusted. For example, what if one started with a bias weight b1 of 100 million – it might never converge since the net(h1) and net(h2) values would hardly be influenced by i1 and i2. Am not totally sure, but it seems only logical that bias weights should also be adjusted the same way w1-w8 are being currently done. If they shouldn’t get adjusted, then it would really be great if someone could explain why.
Ok, everything is clear! But at the moment when I choose for the output layer not a sigmoidal activation function, but linear, what changes in the algorithm?
The derivatives, for example \partial out_h1 / \partial new_h1 will be changed.
Is this same as gradient descent, or that is different from this?
I believe this is gradient descent.
Thankyou very much
What is your suggestion if you have a huge number of input nodes and therefore the sum e.g. neth1 is huge, and so your activation function turns literally every neth1 into 1 because there is a (1 / e^-nethx) in the activation function?
It feels primitive to simply change the function by dividing for example
This is a very insightful question! There are alternative activation functions such as tanh, ReLU, Leaky ReLU etc.. Dead ReLU problem is usually referred as your question. One remedy is to use Leaky ReLU.
I am having the same problem, Your article is very helpful and i designed my neural network based on your article. The problem arises when number of inputs is high and that causes the activation function at the hidden layer to always output a 1. Any suggestions?
Hello, I’m university student in korea.
I study neural netwrok, so I like your writing because it is easy to understand.
Now i make program back propagation in c#.
I have a question one thing. AND gate, OR gate is understand, but
How do I handle actual data?? for example, weather data, fonding data..
Please teach me.
It’s too complicated question for such topic, in fact, this is what professionals use neural networks for. Main and the hardest task for making neural network is choosing parameters and form of input for neural network. You should read some articles about it, but basically you should represent input data in numbers that neural network can work with, choose certain number of hidden and output neurons and then experimentate. Experiments is what neural networks are all about.
Thank you. I wanted solution, but new thing leaned to your reply.
Outstanding explanation Matt ! Appreciate the excellent and detailed walk-through. This will help anybody trying to put together NN’s to get a complete understanding of the underlying math.