
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
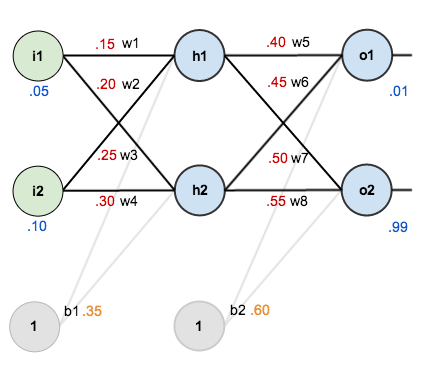
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

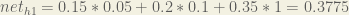
We then squash it using the logistic function to get the output of
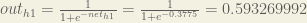
Carrying out the same process for 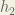
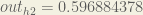
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
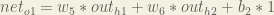
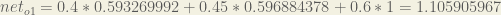

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
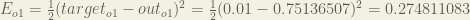
Repeating this process for 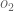
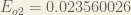
The total error for the neural network is the sum of these errors:
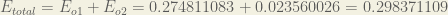
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
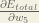
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 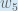 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
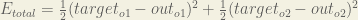
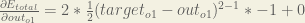
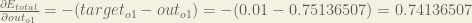
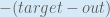
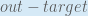
When we take the partial derivative of the total error with respect to 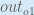

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
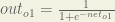

Finally, how much does the total net input of 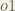
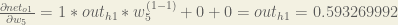
Putting it all together:
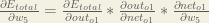
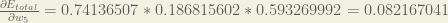
You’ll often see this calculation combined in the form of the delta rule:
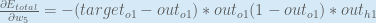
Alternatively, we have 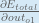
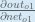

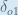


Therefore:
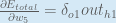
Some sources extract the negative sign from 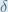
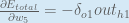
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

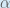 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 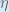 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 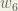

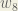
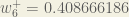
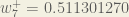
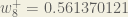
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
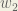
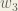
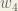
Big picture, here’s what we need to figure out:

Visually:
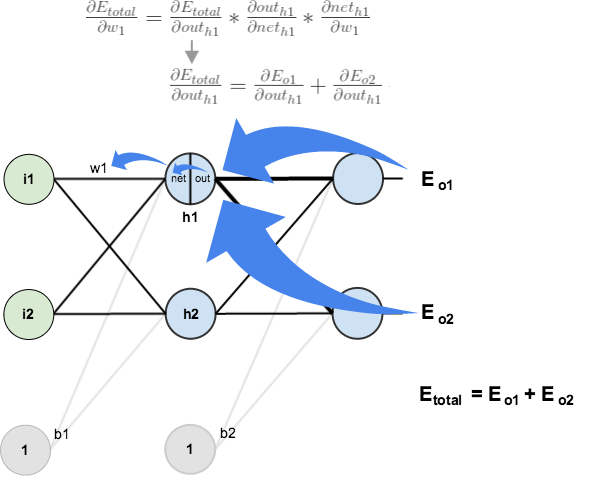
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 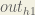
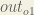
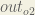
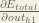
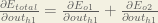
Starting with 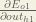
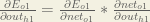
We can calculate 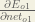
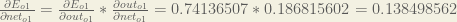
And 

Plugging them in:
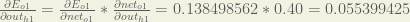
Following the same process for 
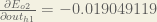
Therefore:
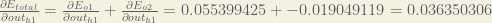
Now that we have 



We calculate the partial derivative of the total net input to

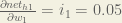
Putting it all together:

You might also see this written as:

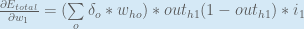
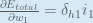
We can now update
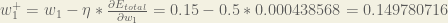
Repeating this for

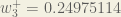
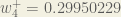
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Hi,
Thank you for this great tutorial.
if it possible, can I translate your sample to Turkish on my MEDIUM essay?
Thanks a lot.
Great article, very detailed and easy to follow.
There is just something that is still unclear for me, more specifically how to calculate the new values for the biases. What bothers me is the fact that each bias is used by two neurons. For instance, b1 is used by h1 and h2.
Then, when using the partial derivative approach to come up with “correction” to the bias, should I do it with regard to h1 or with regard to h2?
Hello
I’d like to ask you when we calculate the partial derivative of E(total) with respect to out(o1), why we have to multiply it with -1.
I love you, writer. Thank you!
I really don’t understand why you calculated it this way:
E/w = E/out * out/net * net/w
instead of just calculating E/w.
E and w are still used in E/out * out/net * net/w and out/out and net/net are always 1. In addition there are more limitations (out and net have to be unequal 0).
Wouldn’t it be shorter and safer to just calculate E/w?
Thank you Very much! Really the best tutorial I have found during the search process of explanation of back propagation for dumbs. The basic has been given very Well.
Thank for this explaination, it is helpfull for me
Can you please give an insight into momentum parameter and the math behind it with an example?
Man this is fantastic. So good. Thank you!
Thank you … your explanation was very clear … it would be good if you translate it to code
This is a great tutorial, but I still can’t figure out how to apply the backward pass on multiple hidden layers. Could you please write something on this topic? Or does anyone have a good practical example for a multiple layered NN?
All you need for backpropagation with multiple layers is here.
Try to read “next hidden layer” instead of “output layer” during the explanation of updating the hidden layer values.
Due to the chain rule, the backpropagation process is local with respect to the layers “above” and “below” the layer you are currently processing. Said another way: what is the error of the output of a hidden layer neuron? It is the weighted sum of the node deltas of the neurons in the next layer.
Thank you!
But what are the target values in this case. How should I replace the (output – target)?
Hi, thanks for the great guide.
This really explains when there is one instance which you have one input and one target value. What if there are multiple instances with lots of input and target pairs. Then what can one do to train the network? Train for each instance and combine the weights?
Thanks
Great.it cleared all my concept.thanks
Thank you for this post ! Your explanation is very clear and easy to understand !
It’s so worthy to understand, Thanks :)
Thank you for your information about this topic. I am confused that you updated w5’s value, it became 0.3589… but later in the second part, you used w5’s value as 0.40.
You should use the weights before the change.
Thank you, now I’m able to understand what is actually going on there
This is really fantastic
I was struggling to find a numeric example to practise it, thank you very much
Thanks ,really help me to understand back prop
Awesome tutorial. I really understood ” propagating the error backwards” concept for the first time.
By testing to encode the algorithm and obtaining all Wn+ correct at first update, is it possible to have a error in calculation code? My second update TotalError is wrong (0.342613).
I think I’ve found an error for the partial d(out_o1)/d(net_o1). You said d(out_o1)/d(net_o1) = out_o1(1 – out_o1) but it should be d(out_o1)/d(net_o1) = net_o1 (1 – net_01). Other than that, great post!
Nevermind! Silly mistake on my part (was too tired).
I think it is not correct
Based on the chain rule, d(out_o1)/d(net_o1) should be (e^(-net_o1)/((1 + e^(-net_o1) ^ 2)
Sorry. My bad. The value is exactly same as f(x) * (1 – f(x).
so, d(out_o1)/d(net_o1) = out_01 * (1 – out_01)
I`d like to express my gratitude. I have been stuck on this Week’s. And now I think I got the basis. So I can walk without crutch and continue my course. Great explanation
Carlos valls
Reblogged this on Kernel Panic.
I finally understand! I remember bookmarking this post early this year or mid last year but I didn’t understand it. However, after brushing up on my derivatives now I do! Thank you so much for this comprehensive tutorial!
thanks for the post :)
but what about the bias? dont we need to update it?
ive tried it, and my neural network can learn without updating the bias, thanks
This link will show you the importance of the bias:
https://stackoverflow.com/questions/2480650/role-of-bias-in-neural-networks
It can learn without the bias, but it is not practical in larger problems. Bias needs to be updated.
its really helpful
Thank You…it so explanatory.
Hi Matt. Thanks you I was learn to implement it on GPU easily. https://github.com/stormcolor/gbrain
Regards ;)
This is exactly what ‘A Step by Step Backpropagation Example’ should be! Thanks for the great post!!
This is indeed a very good explanation . I tried to understand andrew ng ‘s course, which is really a brilliant course. But how does back propagation derivatives works, i had some problem in understanding . This explanation makes me feel great as now i understand it fully . Thanks Mazur.
This is wonderful. Thanks for the presentation. Can we then conclude that for a backpropagation algorithm to produce optimal results, the number of iterations or epoch must be large? Is there any way around this for the network to learn faster with minimum iterations? Thanks.
I’m korean. Your explanation is best of best!
Thank you for ginving this story.
you are not updated the bias ,please ensure me that it is necessary or not.
Your explanation is awesome. Thanks a lot.
I was really struggling with this, thanks for breaking it down and explaining it so well !
Hey,
A really great explanation, thanks for sharing the knowledge.
so glad i stumbled across this site! youre my new fav blog as im a mechanical engineer shifting more towards data science/deep learning for autonomous vehicles and i enjoy playing NLHE – one stop shop for all my interests! got a lot of old posts to sift through – great work and documentation! very good simple explanations and a nice clean layout – keep up the good work!
For multi-class classification with neural networks having regularisation parameter, we have a different kind of cost function involving each and every weight and term including regularisation parameter multiplied with weights, does this regularisation parameter will affect the backpropagation algorithm????
I have written the corresponding code for a 4-7-2 network. the training mean squared error decreases well but the problem is that when I apply the updated weights and biases to the network at each iteration in order to check the validation error (the validation data set is applied randomly), the validation error increases badly. that is why the test fails. I do not have any idea what is the reason behind this.
I was wondering if somebody gives me some advice to deal with such issue.
Thanks
Very detailed & thorough explanation … much appreciated! Python code to implement this example. I am not a developer, so am sure there are more efficient/elegant ways of coding this.
https://github.com/vendidad/DS-repo/blob/master/Backpropagation%20-%20Consolidated%20Script.ipynb
Hi Matt:
Thank you very much for this awesome explanation.
A major component Back propagation is finding out how a weight affects total error, correct?
With that being said, from the breakdown of dEtotal/dw5, the only factor that involves w5 is dnetout/dw5. But this simply breaks down to hout1. I am failing to see how tweaking of w5 is done here, aside from w5+ = w5 – alpha(dEotal/dw5).
My question is also more geared towards what happens when the weight we compute increases the total error.
This is great! Thank you for the step by step explanation
Fantastic write up. Many thanks.
Do you really update the link weights by just subtracting the update from the last weight? I am asking because I have just repreduced the example and after 10,000 iteration some weights go into the -3 and 2 area. If I look at the equations it seems to confirm that there is nothing that prevents this.
I was under the impression that both link and node weights need to be in the 0,1 or -1,1 interval. Maybe this assumption is wrong?