
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
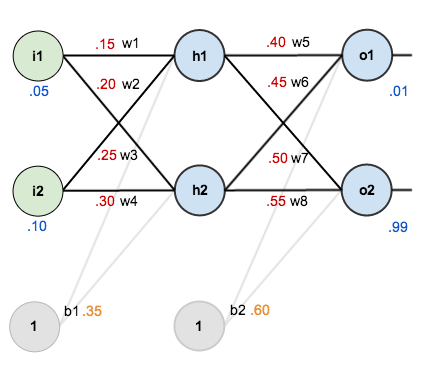
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

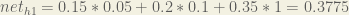
We then squash it using the logistic function to get the output of
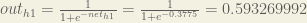
Carrying out the same process for 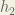
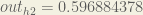
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
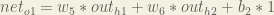
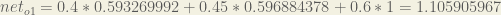

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
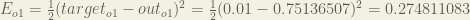
Repeating this process for 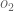
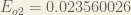
The total error for the neural network is the sum of these errors:
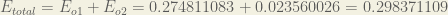
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
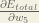
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 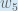 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
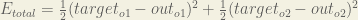
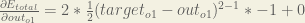
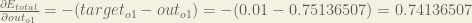
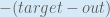
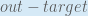
When we take the partial derivative of the total error with respect to 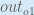

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
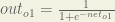

Finally, how much does the total net input of 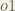
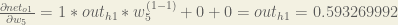
Putting it all together:
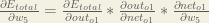
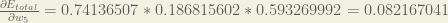
You’ll often see this calculation combined in the form of the delta rule:
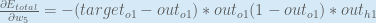
Alternatively, we have 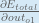
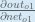

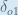


Therefore:
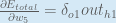
Some sources extract the negative sign from 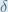
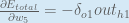
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

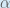 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 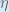 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 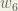

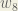
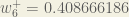
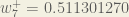
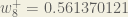
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
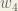
Big picture, here’s what we need to figure out:

Visually:
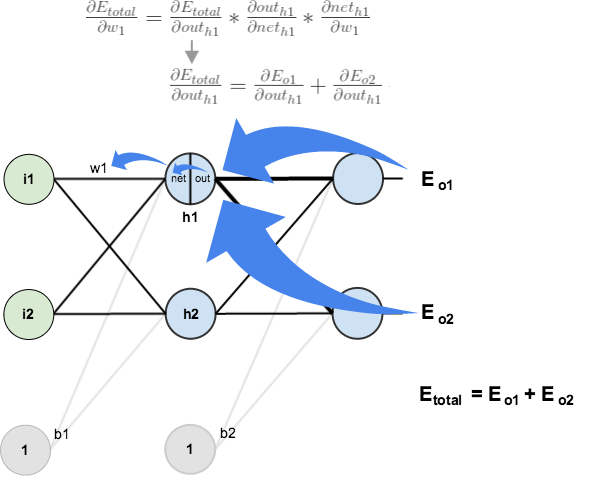
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 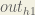
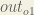
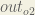
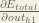
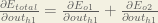
Starting with 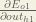
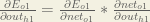
We can calculate 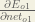
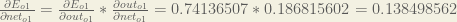
And 

Plugging them in:
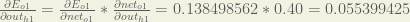
Following the same process for 
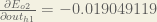
Therefore:
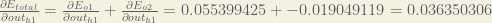
Now that we have 



We calculate the partial derivative of the total net input to

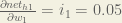
Putting it all together:

You might also see this written as:

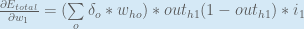
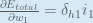
We can now update
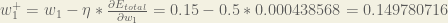
Repeating this for

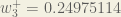
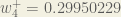
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

I think the formuale below is wrong. You should apply the multivariable version of the chaine rule instead.
\frac{\partial E_{total}}{\partial w_{5}} = \frac{\partial E_{total}}{\partial out_{o1}} * \frac{\partial out_{o1}}{\partial net_{o1}} * \frac{\partial net_{o1}}{\partial w_{5}}
Hi, it seems your network visualization is giving an error. numInputs not defined. Please, let me know when it is working, I’d like to check whether I can reference or include it into my materials.
Best
Ingo Dahn
I’m assuming only one weight on the bias is just for simplicity?
Although this is a good post. I don’t think the writer understand about bias, that’s why there’s no concrete explanation about how to update bias in this post.
The author likely assigned the same bias for the hidden and output neurons for simplicity. The article does not show the step of updating the bias weights, presumably as it is the exact same process as is used to update other weights (it is actually simpler, since the bias node activation is always 1.)
Can give someone one example for updating one bias? I don’t know, how i can update one bias-
You can image that a bias of one of your nodes is just a weight from another node with the constant ‘out’ of 1. Since that node only goes to your node, it only has an outgoing edge, and no incoming edges (in degree = 0) which means that the out never changes because the net never changes because there are no inputs to that node.
With that in mind, you can update the bias by updating the weight of the outgoing edge from the bias node to your node.
I like how you put this, will help for my exam tomorrow
Correct observation. The bias is not updated, therefore the total error in the first round and the second round goes like this:
Matt: E=0.298371109 -> E=0.291027924
If you correctly update the bias also, then it should be like this:
Barek: E=0.298371 -> E=0.280471
When I did not update the bias, just like Matt, then I got
Barek: E=0.298371 -> E=0.291028
This proves that Matt did not update the bias.
Anyway, this is a great post. Thank you, Matt!
Thanks to such the nice explanation!
I implement my first neural network by referring the post, thanks.
hello!
If there are multiple hidden layers, say two, three, or even more; How do you continue the back-propagation? Do you always take it two layers at a time?
If we are dealing with the leftmost hidden layer, do we need to track how changes to weights in this layer effect the following multiple hidden layers and then finally the output layer (working out error)
Tracing all routes that changes in a far left weight effect error seems to “blow up” very quickly so to speak.
Can anyone point me towards a worked example with at least 1 more hidden layer?
Hello Justin,
the back-propagation works also with multiple hidden layers.
You will find a good visualization for neural networks:
http://playground.tensorflow.org/
Sincerly
Albrecht
Justin, did you find a solution to your problem, like you all I need to see is one more hidden layer backpropagation – i.e. 2 hidden layers!
Wm. Jenkinson
Thank you for your detailed explanation.
I wonder how you set the outputs to be 0.01 and 0.99 ?
It is arbitrary chosen? Does the amount of the inputs and their vaules impact of the decesion how to set the outputs?
This is multi-label classification, correct?
Otherwise I would be wondering why we don’t either use a softmax in the last layer? Also our outputs don’t sum to 1.
Thank you and kind regards
Hmm, in my case, after first round of backpropagation the total error is 0.291027774 instead 0.291027924. And after repeating 10,000 times, the total error is 0.0000351019 instead 0.0000351085. Тhe rest of the calculations matched perfectly
Same, I wonder if that is my own issue or some floating point magic. The network seems to be learning…
I’m totally stumped, I’ve been over this article like 100 times and scrolled through as many comments and I cannot figure out how back propagation would work with multiple hidden layers. Using the example (I’m using d instead of the swirly thing because I’ve seen other comments do that and idk how to type the other character):
dEtotal / dW1 = dEtotal / dOutputH1 * stuff I get
dEtotal / dOutputH1 = dEo1/dNeto1 + same for O2
dEo1/dNeto1 = dEo1 / dOutputo1 * dOutputo1 / dNeto1
dEo1 / dOutputo1 = -(targeto1 – outputo1)
I understand that for the output layer, but if you have a second hidden layer in place of the output layer then for some hn
dEhn / dOutputhn = -(targethn – outputhn)
What the hell is the target value? I’ve been pulling my hair out for like 4 hours and I cannot figure it out.
You need to work backwards through the layers and use the ‘delta’ from the next layer’s neurons. This delta should be stored whilst you are working backwards. The delta is the derivative of the current neurons output multiplied by the sum of all output neurons deltas * the weight between that neuron and the current one.
So what you see in the blue box “You might also see this written as” works but replace input i, with the current neurons output passed through the derivative of the activation function
Same. Have been searching for 2 days till now…
I also found a website with clear formulas and definitions to compute multiple hidden layer weights. Hope this help!
https://brilliant.org/wiki/backpropagation
Hi, i noticed that the value of out_h2 is incorrect. since its a logistic function, the sum of the two output can never exceed one but should approximate one in the nearest whole number. i go the value as 0.34468163
OMG I’m a postgrad student and have learnt about CV,NLP which all covers NN but I’m still confusing with the math behind the learning. Thanks for your detailed formulas and calculations!!
Cheers,
Jiayu
This is such a good, detailed exaplanation. Thank you very much, it helped a lot.
I have written my own implementation and can verify I get the same results. Great! Now I am trying to add the bias.
Firstly, My understanding was that the bias b1 would have 2 distinct weights being fed in to h1 and h2. And similarly b2 would have 2 distinct weights for o1 and o2. The article suggest that it is a single common weight for b1 -> h1,h2 and a single weight for b2 -> o1,o2. Which is correct?
Secondly, when using the derivative of the activation function for the bias, is this just f'(1) always since the bias ‘output’ is always 1?
1.
You really should have distinct bias values for h1 and h2, but both can start from the given 0.35. These values will change during backpropagation. The same is true for o1 and o2. So after one backpropagation step:
hidden_layer->b[0]=0.345614 hidden_layer->b[1]=0.345023
output_layer->b[0]=0.530751 output_layer->b[1]=0.619049
2.
When using the derivative of the activation function, you start from out values and get back to net values. This is the “activation backward” step, and bias has no effect here. It will be updated in the next step, the “layer backward” step, which is matrix calculation.
brilliant!!! thank you a lot!! you helped me very much!!!
Is there a mistake for w7+ ? I find 0.431 instead of 0.511. The other w+ seem fine.
Great detailed explanation. Thanks a million, it helped a lot.
Can you please send me BPNN python code using keras library
Very nicely explained. Can you please explain if there are more than one hidden layer what is done? I mean the repetitive portion which is iterated backward any worked example will be a great help.
In 2023 this blog still benefits newbie in learning neural networks. What an attempt! Thank you.
Thank you very mach Matt.
I develop my own Neural Net using Delphi, and the values are exactly the same!
I adding hidden layers:
1 Hidden layer -> 0.0000351020 (the same of the article)
2 Hidden layer -> 0.0000061176
4 Hidden layer -> 0.0000049050
I put 0.5 to all bias(s), and change the learning rate (with 1 hidden layer):
Learning rate 0.50 -> 0.0000277005
Learning rate 0.75 -> 0.0000116993
Learning rate 0.85 -> 0.0000086999
Best Configuration (4 hidden layers, bias = 0.5, learning rate = 0.85)
0.0000008945
oh my god my eyes.
oh my god my brain.
ahhhhhhhhhh
Oh really
I think the net_h1 = 0.3775 calculated in the example is wrong. The second weight applied to h1 is w3 = 0.25, not w2 = 0.2 as used in the example, thus net_h1 should be 0.05 * 0.15 + 0.1 * 0.25 + 0.35 = 0.3825
Thanks Matt, for leaving the just enough bread crumbs. I’ve implemented this network entirely in Shell Script, using my iQalc Calculator, which is also written in shell.
Beyond my expectations, I get exactly the same output, +-1ulp, even after 10,000 epochs. You can see the code here:
https://github.com/ShellCanToo/nn-demos
or get the code with:
git clone https://github.com/ShellCanToo/nn-demos
Here’s F# code (with biases updated too):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
output
hosted with ❤ by GitHub
Thanks Matt!
This was meant to be a link to the code, not regurgitated here!