
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Continue learning with Emergent Mind
If you find this tutorial useful and want to continue learning about AI/ML, I encourage you to check out Emergent Mind, a new website I’m working on that uses GPT-4 to surface and explain cutting-edge AI/ML papers:

In time, I hope to use AI to explain complex AI/ML topics on Emergent Mind in a style similar to what you’ll find in the tutorial below.
Now, on with the backpropagation tutorial…
Overview
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
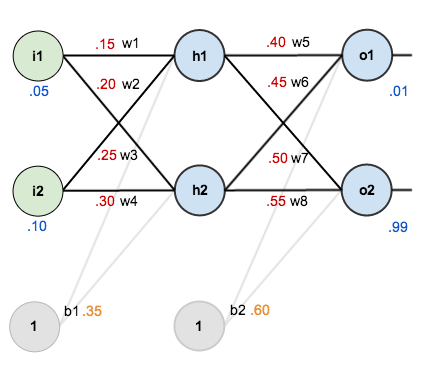
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Here’s how we calculate the total net input for 

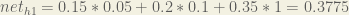
We then squash it using the logistic function to get the output of
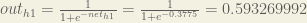
Carrying out the same process for 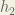
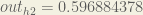
We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 
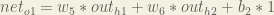
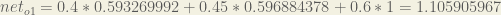

And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:

 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [1].For example, the target output for
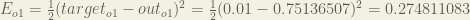
Repeating this process for 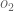
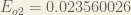
The total error for the neural network is the sum of these errors:
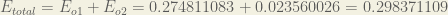
The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 
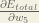
 is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to 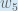 “. You can also say “the gradient with respect to ”.
“. You can also say “the gradient with respect to ”.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
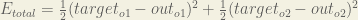
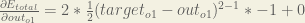
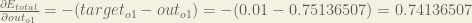
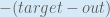
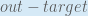
When we take the partial derivative of the total error with respect to 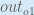

Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:
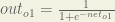

Finally, how much does the total net input of 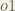
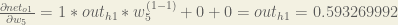
Putting it all together:
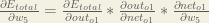
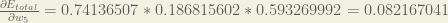
You’ll often see this calculation combined in the form of the delta rule:
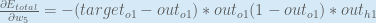
Alternatively, we have 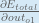
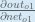

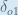


Therefore:
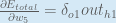
Some sources extract the negative sign from 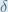
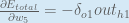
To decrease the error, we then subtract this value from the current weight (optionally multiplied by some learning rate, eta, which we’ll set to 0.5):

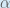 (alpha) to represent the learning rate, others use
(alpha) to represent the learning rate, others use 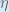 (eta), and others even use
(eta), and others even use  (epsilon).
(epsilon).We can repeat this process to get the new weights 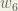

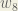
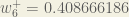
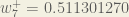
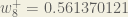
We perform the actual updates in the neural network after we have the new weights leading into the hidden layer neurons (ie, we use the original weights, not the updated weights, when we continue the backpropagation algorithm below).
Hidden Layer
Next, we’ll continue the backwards pass by calculating new values for 
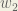
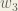
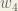
Big picture, here’s what we need to figure out:

Visually:
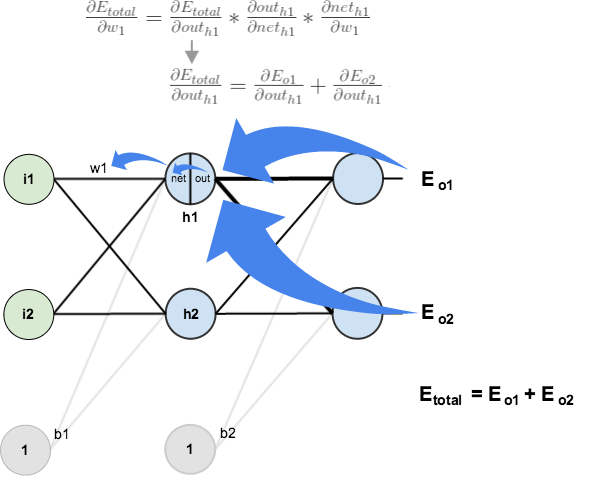
We’re going to use a similar process as we did for the output layer, but slightly different to account for the fact that the output of each hidden layer neuron contributes to the output (and therefore error) of multiple output neurons. We know that 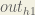
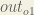
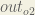
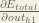
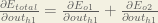
Starting with 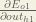
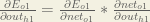
We can calculate 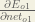
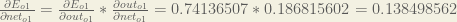
And 

Plugging them in:
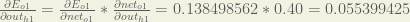
Following the same process for 
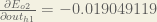
Therefore:
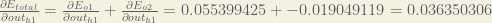
Now that we have 



We calculate the partial derivative of the total net input to

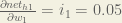
Putting it all together:

You might also see this written as:

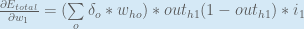
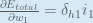
We can now update
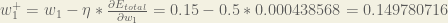
Repeating this for

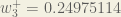
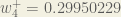
Finally, we’ve updated all of our weights! When we fed forward the 0.05 and 0.1 inputs originally, the error on the network was 0.298371109. After this first round of backpropagation, the total error is now down to 0.291027924. It might not seem like much, but after repeating this process 10,000 times, for example, the error plummets to 0.0000351085. At this point, when we feed forward 0.05 and 0.1, the two outputs neurons generate 0.015912196 (vs 0.01 target) and 0.984065734 (vs 0.99 target).
If you’ve made it this far and found any errors in any of the above or can think of any ways to make it clearer for future readers, don’t hesitate to drop me a note. Thanks!
And while I have you…
Again, if you liked this tutorial, please check out Emergent Mind, a site I’m building with an end goal of explaining AI/ML concepts in a similar style as this post. Feedback very much welcome!

Superb Explaination
I m not getting if same inputs need to regenerate why we are putting hidden layers ,whats is the purpose?
just awesome explanation…!!
Took a pen and paper and really enjoyed this. Thanks!
This is simply the best explanation I have found for back propagation
Love how you broke everything down!!
Here is another very nice tutorial with step by step Mathematical explanation and full coding.
http://www.adeveloperdiary.com/data-science/machine-learning/understand-and-implement-the-backpropagation-algorithm-from-scratch-in-python/
This link has awesome description of backprop. Thanks!
This is the best tutorial on neural work! All textbooks should be written like this. Thank you very much!
This really was the greatest explanation! Love it. Thanks
Great! Thanks for the walk through! When using different activation functions…. during back propogation we just need to use the derivative of the activation function yes?
Teaching is an art! Good Post!
Thank you very very very useful topic
Best explanation for back propagation with clear steps..thanks a lot…
This is a gem! Thanks so much, Matt! You made me understand in an hour what a semester in grad school failed to do!
Such a wanderful and simple explanation
Goshhhh….. I am so happy I came across this post. Such a clean way of explanation. Thanks Matt.
Amazing article, can’t recommend enough ! Not ashamed to cover the math step by step which I am sure not every teacher is always willing to do. Understand it once and the rest will come with it.
Thank you very much, you are artist on deep learing!
Was looking for exactly this kind of a blog! Thanks!!!
wow its amazing
I just wanted to comment that this blog post has served me well for the last 4 years. I mess with neural networks as a hobby and while I mainly create art pieces that use the chaotic dynamics inherent in these networks, sometimes I like to play around with making something that can learn and this is my go-to read for remembering how to do backpropagation. It saves me so much time! So I’d just like to personally say thank you.
Appreciate you saying so!
Excellent explanation !
Don’t you think the hidden nodes should have different bias values? You’re using the same values for hidden nodes on the same layer.
I have the same doubt! It’s a pity the author isn’t replying. I suppose he must’ve done it for the sake of simplicity but that would defeat the purpose of the article, wouldn’t it? Maybe as an empirical rule the biases for a layer are to be initialized as the same value?
I’m betting you just use the chain rule that he uses throughout and the summation that he uses for the hidden layers. Modifying what he says: “We know that b_{2} affects both out_{o1} and out_{o2} therefore the \frac{\partial E_{total}}{\partial b_{2}} needs to take into consideration its effect on the both output neurons”
What about bias values?
Great material! Thank you so much for your effort! Your idea of plugging numbers into the equation was a great aid in developing understanding and intuition behind this. Will read this many times over until required.
Thank you sir !!
This is an awesome tutorial, thank you very much. I only struggle at one point, namely the Backward Pass, Output Layer. You write
E_Total = 1/2 (target_o1 – out_o1)^2 + 1/2 (target_o1 – out_o2)^2
That is clear to me. But then the next line reads:
φE_Total/φout_o1 = 2 * 1/2 (target_o1 – out_o1)^2-1 * -1 +0 <<– Where is the '-1' coming from? I spend an hour trying to understand it, but I just don't. Any help would be greatly appreciated.
Hannah
If you use the correct partial-derivative without the -1, you would need to add the new weight onto the old one (not subtract them), so it’s a unexplained side-product that everyone seems to use.
1/2 (target_o1 – out_o1)^2
the derivative of this function states that:
a) the exponent becomes the multiplier, so:
1/2 (target_o1 – out_o1)^2
becomes
2 * 1/2 (target_o1 – out_o1)^2
b) subtract 1 from the exponent, so:
2 * 1/2 (target_o1 – out_o1)^2
becomes
2 * 1/2 (target_o1 – out_o1)^2-1
c) the inner function g(x) = out_o1, so:
2 * 1/2 (target_o1 – x)^2-1
d) the “x” has 1 as exponent. The derivative states that it should be subtracted by 1, so:
2 * 1/2 (target_o1 – x^1-1)^2-1
which results in
2 * 1/2 (target_o1 – x^0)^2-1
e) every number powered by zero becomes 1, so:
2 * 1/2 (target_o1 – 1)^2-1
f) it is a composite function, so applying the chain rule:
f′(g(x))⋅g′(x)
g'(x) = -1
the -1 is g'(x). The remaining before it is f'(g(x))
The -1 comes from the derivative of -out_o1 within the parenthesis.
Excellent story about backpropagation. I tried to make a C++ implementation. I managed to do the same numeric values for the weights. However there is no lines about the bias adjusting. Can biases b1 and b2 adjusted like weights, where the inputs always 1.0 ?
Thanks
Thanks for your explanation, is good, however, I can’t see how Bias could adjust. could you help us. Tks
PLEASE, answer me, the term d(E_o2)/d(out_h1) should be -0.02229036407211166… check pleaseeee
Anyway, best explanation on internet
This is a really nice explanation. Good job.
Bless your heart… Thank you.
Excellent explanation! Would love to see the calculations followed through for the biases too.
Thank you so much for writing this awesome blog. I greatly appreciate your efforts
I am unable to understand net_o1 = w_5 * out_h1 + w_6 * out_h2+ b_2 * 1. how does the derivative translate into 1 * out_h1 * w_5^(1 – 1) + 0 + 0 = out_h1 = 0.593269992, from where did w_5^(1-1) come from shouldnt it just be 1 * out_h1 * w_5^(1 – 1)
I am unable to understand net_o1 = w_5 * out_h1 + w_6 * out_h2+ b_2 * 1. how does the derivative translate into1 * out_h1 * w_5^(1 – 1) + 0 + 0 = out_h1 = 0.593269992, from where did w_5^(1-1) come from shouldnt it just be 1 * out_h1 * w_5^(1 – 1)
Best explanation i’ve ever seen.
Hi Matt
This review is one of the best I have ever seen. Thanks for your efforts.
Joe Scanlan email: scangang5@aol.com
Congratulations. Really a good tutorial. Just what I was looking for.
Man, you saved my life. I was looking for a proper, but easy to understand backprop tutorial. God bless you.
Bravo! The most readable demonstration of how back propagation actually works so far!
holly cow really helpful! Thanks so much!
Can anyone please explain how did he get the value -0.019049119? I always get something different.
Best explanation with simple example!
Cheers
why for updating w7 & w8 you put negative (-) on “the gradient with respect to w7”?
I have no idea about this because at the first you didnt put (-) for updating w5 & w6. it is change my w7 & w8 updating result if I don’t use that (-)
That explanations needs a bottle of champagne,well explained.
This is the best tutorial on neural work! All textbooks should be written like this. Thank you very much!
bravo